Regresión de Cox
Andrea Silva 
Micaela Gauto
Introducción
Hasta el momento hemos visto cómo efectuar estimaciones paramétricas y no paramétricas de la función de supervivencia y de la función de riesgo, que permiten describir la evolución de la “supervivencia” de una población. También hemos visto cómo comparar curvas de supervivencia, al estratificar por las distintas categorías de una variable categórica.
El análisis de supervivencia dispone también de modelos de regresión, que permiten identificar y evaluar la relación entre un conjunto de variables explicativas y el tiempo de supervivencia (variable respuesta), por lo que se la considera parte de los modelos lineales generalizados. A continuación, presentaremos uno de los modelos más usados en salud: el modelo de regresión de Cox, llamado así en honor a su creador (Cox 1972).
La regresión de Cox, también llamada modelo de riesgos proporcionales (proportional hazards model) es una técnica muy difundida. Está indicado su uso cuando la variable dependiente esté relacionada con la supervivencia de un grupo de sujetos o, en general, con el tiempo que trascurre hasta que se produce en ellos un suceso o evento. Como ya dijimos, el evento de interés no tiene por qué ser la muerte, puede ser otro tipo de suceso, por ejemplo, el fallo de una prótesis, la incidencia de una enfermedad o la ocurrencia de una complicación en quien ya tiene una patología de base. Se usa para valorar simultáneamente el efecto independiente de una serie de variables explicativas o factores pronósticos sobre esta supervivencia (es decir, sobre la tasa de mortalidad) o sobre la tasa de ocurrencia de otro fenómeno que vaya ocurriendo tras un periodo de tiempo variable en cada sujeto. Como en cualquier modelo de regresión, las variables explicativas pueden ser tanto cuantitativas como categóricas.
La regresión de Cox es la extensión multivariada del análisis de supervivencia para evaluar de manera general variables dependientes del tipo “tiempo hasta un suceso o evento” y usa modelos de regresión, próximos al modelo de regresión logística. Es una técnica que permite identificar y evaluar la relación entre un conjunto de variables explicativas y la tasa de ocurrencia del suceso de interés.
La mayor utilidad del modelo de regresión de Cox radica en que permite predecir las probabilidades de supervivencia (o, en general de permanencia libre del evento) para un determinado sujeto a partir del patrón de valores que presenten sus variables pronósticas.
Al igual que en la regresión logística, en la regresión de Cox también es necesaria una función matemática que transforme el desenlace y permita entender la relación entre las variables por medio de un modelo similar al de la línea recta. Y en esto nos concentraremos a continuación.
Modelo de Cox
El modelo de Cox es un modelo semi-paramétrico que postula que:
\[ h(t,x) = h_o(t) exp (x_1\beta_1+x_2\beta_2+\dots+x_n\beta_n) \]
donde,
\(h (t,x)\) : representa el riesgo de morir al tiempo \(t\) de un sujeto que tiene un patrón determinado de las variables \(x\).
\(h_0(t)\): representa el riesgo basal dependiente del \(t\).
En este caso, como podemos ver, la función que es “transformada” es la función denominada Hazard, que puede simplificarse en términos prácticos como una medida del riesgo instantáneo de ocurrencia de dicho evento.
Como podemos ver, este modelo asume un presupuesto importante: las covariables tienen un efecto multiplicativo sobre la función de riesgo. ¿Qué significa esto? Esto significa que la razón entre el riesgo de ocurrencia del evento para dos individuos: individuo i e individuo j, por ejemplo, con covariables:
\(xi= (xi_1, xi_2, xi_3,\dots,xi_n)\) (es el conjunto de covariables del individuo i) \(xj= (xj_1, xj_2, xj_3,\dots,xj_n)\) (es el conjunto de covariables del individuo j) será: \[ \frac {hi(t/xi)} {hj(t/xj)}= \frac{ho(t)exp(xi_1\beta_1+xi_2\beta_2+\dots xi_n \beta_n)}{ho(t)exp(xj_1\beta_1+xj_2 \beta_2+\dots xj_n \beta_n)} \] Entonces:
\[ \frac {hi(t/xi)} {hj(t/xj)}= \frac{\cancel{ho(t)} exp(xi_1\beta_1+xi_2\beta_2+\dots xi_n \beta_n)}{\cancel{ho(t)}exp(xj_1\beta_1+xj_2 \beta_2+\dots xj_n \beta_n)} \]
O sea que este cociente de riesgos, como podemos ver, es independiente del tiempo. Por este motivo, el modelo de Cox se lo conoce también como Modelo de Riesgos Proporcionales. Es un modelo semi-paramétrico, pues no asume ninguna distribución para la función de riesgo basal \(ho(t)\), la única asunción es, como ya dijimos antes, que las covariables tienen un efecto multiplicativo sobre la función de riesgo, y esto constituye la parte paramétrica del modelo.
En la regresión de Cox, por lo tanto, el efecto de las variables independientes se presenta como un Hazard Relativo (HR), y expresa la magnitud en la que una variable aumenta o disminuye el riesgo de ocurrencia de un desenlace en el tiempo.
Como en todo modelo, tendremos que estimar los coeficientes (\(\beta\)) y aprender a interpretarlos. A continuación aprenderemos a construir un modelo de Cox, fijaremos criterios para seleccionar el mejor modelo, evaluaremos el ajuste de dicho modelo y veremos algo de análisis de residuos. Allá vamos!
Estimación e interpretación de los coeficientes del modelo de Cox
Los coeficientes del modelo de Cox son estimados por el método de verosimilitud parcial, pero su desarrollo lo omitiremos, dado que los paquetes estadísticos, los calcularán por nosotros. Para comprender su interpretación, consideraremos el modelo más simple, con una única covariable:
\[ h(t,x)= ho(t) e^{\beta x} \] Si se calcula el cociente entre la tasa de riesgo instantáneo para una variable que toma los valores \(x=0\) y \(x=1\): \[ HR= \frac{e^{(\beta*1)}}{e^{(\beta*0)}}= e^\beta \]
¿Cómo interpretamos esto? Sé que ya todos tienen mucha experiencia en interpretar correctamente expresiones de este tipo (notarán ciertas similitudes con la regresión logística), pero nunca está de más reforzar.
Si la variable es dicotómica, por ejemplo consideremos sexo, donde \(x=1\) corresponde a masculino y \(x= 0\) a femenino, diremos que los varones ven incrementado su riesgo en \(e\beta\) respecto de las mujeres.
Si la variable fuera continua, como por ejemplo la edad, diremos que un incremento de un año en la edad, aumenta el riesgo en \(e\beta\). Si calculamos el cambio en \(h\) para \(n\) variables explicativas, y observamos el coeficiente para cuando cada \(xi\) se incrementa en una unidad, manteniendo constante al resto, observaremos algo similar.
Si aplicamos ln a la expresión del HR, tendremos que: \[ lnHR= \beta \]
Como acabamos de ver, la interpretación del modelo de Cox no se hace directamente a través de su coeficiente estimado \((\beta)\) sino del exponencial del coeficiente estimado, \(exp(\beta)\).
Para variables dicotómicas \(exp(\beta)\) es un estimador de la razón de riesgos (Hazard Ratio) y se interpretará en forma análoga al RR: valores mayores que 1 indican sobreriesgo para el grupo “expuesto”, valores menores a 1 indican factor de protección. Para variables continuas, su interpretación es más difícil ya que no es estrictamente un RR, pero lo podemos pensar como algo similar a un RR para un incremento de la variable continua. Para comprender mejor lo que hemos visto hasta aquí y lo que seguiremos viendo, vamos a recurrir a un ejemplo.
Ejemplo práctico en R
Retomaremos el ejemplo sobre trasplante de médula ósea (TMO), que vimos cuando abordamos la estimación de Kaplan Meier. Recordemos que los datos del archivo “tmo.txt“ provienen de esa cohorte de 96 pacientes sometidos a trasplante de médula ósea. Las covariables registradas para cada paciente se describen en la siguiente tabla:
Las variables presentes en el conjunto de datos son las siguientes:
id: identificador único del pacientesexo: sexo biológico (M = masculino, F = femenino)edad: edad en años al momento del trasplantestatus: estado al final del seguimiento (1 = fallecido, 0 = censurado)tiempo: tiempo hasta la fecha de óbito o censuradeag: presencia de enfermedad injerto-huesped agudadecr: presencia de enfermedad injerto-huesped crónicafase: fase de la LMC (aguda, crónica, crisis blástica)
Comenzaremos por activar los paquetes necesarios:
Leemos el archivo de datos
En general, no se realiza la regresión de Cox con cada una de las variables para decidir cuál incluir en el modelo (puede hacerse para ver el cambio de los coeficientes), sino que esta decisión se toma en base a las curvas de KM, considerando las variables en las que se observan diferencias. Como el modelo de Cox, en general se usa con fines predictivos, pueden ser incluidas otras variables que clínicamente se consideren relevantes.
Vamos a considerar un modelo inicial que incluya todas las variables (m1) y luego usaremos un procedimiento “hacia atrás” manual. El modelo semiparamétrico de riesgo proporcionales de Cox es realizado con la función coxph() del paquete survival:
Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag + sexo +
edad, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.344438 1.411197 0.542408 0.635 0.525417
fasecrónica -0.593973 0.552129 0.371427 -1.599 0.109784
decrsi -1.061750 0.345850 0.338452 -3.137 0.001706 **
deagsi 1.190381 3.288332 0.327485 3.635 0.000278 ***
sexoM 0.271984 1.312567 0.332115 0.819 0.412816
edad -0.005019 0.994993 0.014912 -0.337 0.736415
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4112 0.7086 0.4874 4.0859
fasecrónica 0.5521 1.8112 0.2666 1.1434
decrsi 0.3459 2.8914 0.1782 0.6714
deagsi 3.2883 0.3041 1.7307 6.2479
sexoM 1.3126 0.7619 0.6846 2.5166
edad 0.9950 1.0050 0.9663 1.0245
Concordance= 0.768 (se = 0.03 )
Likelihood ratio test= 40.67 on 6 df, p=3e-07
Wald test = 38.46 on 6 df, p=9e-07
Score (logrank) test = 47.62 on 6 df, p=1e-08La columna “
coef” indica los valores de \(\beta\) .La columna “
exp (coef)” indica los valores de \(HR\).La columna “
se (coef)”: desvío estándar de los coeficientesZyPr (<|Z|): estadístico del Test de Wald y su p-valor.lower.95yupper.95: 95% IC para los \(HR\).
En la parte inferior, destacamos el LR test del modelo.
Además de lo señalado, se agregan el valor de Concordancia así como los estadísticos de prueba, grados de libertad y p-valores de las pruebas de hipótesis de Razón de Verosimilitud, Prueba de Wald y Prueba de Puntajes (score test).
Repasemos:
El test de Wald : Testea solo un parámetro, por ejemplo la \(Ho: \beta_3=0\). El test estadístico es \(Z=\frac{\beta}{EE\beta}\) que sigue una distribución aproximadamente \(N(0,1)\). \(LR\) y \(Z\) son aproximadamente iguales en grandes muestras, pero pueden diferir en muestras pequeñas.
La Deviance puede ser utilizada tanto para obtener una estadística global de ajuste del modelo, como para comparar modelos. Recordemos que: \(D= 2 (log\ Likelihood\ modelo- log\ Likelihood\ modelo\ nulo)\), donde el Modelo nulo es un modelo teórico sin covariables.
Podemos calcular el Criterio de Información de Akaike (AIC) y también el Criterio de Información Bayesiano (BIC). El AIC sirve para comparar la plausibilidad relativa de un conjunto de modelos. Es decir, dado un conjunto de modelos construidos con los mismos datos, el AIC los ordena según su verosimilitud dados los datos con que se construyen. Este criterio tiene en cuenta tanto el ajuste del modelo como su complejidad de acuerdo a la fórmula: \(-2*log(-Likelihood) + k*npar\) donde el primer término mide el ajuste (es la deviance) y el segundo la complejidad (\(npar\) es el número de parámetros y \(k = 2\)).
AIC mide lo lejos que está el modelo de la realidad (de un ‘modelo perfecto’), por lo que cuanto menor es el valor, más plausible es el modelo. Existen otros criterios parecidos como el BIC (en BIC \(k = log(n)\)).
AIC no equivale a significación; de hecho este criterio se plantea dentro de una concepción de la estadística distinta –y alternativa– a la fundamentada en testado de hipótesis. El comando es simplemente:
# Criterio de información de Akaike
AIC(m1)[1] 378.1393# Criterio de información Bayesiano
BIC(m1)[1] 389.4903El Likelihood nos da una evaluación cuantitativa de la compatibilidad de los datos con determinado valor del parámetro. \[ Likelihood\ Ratio= \frac {Likelihood\ del\ modelo}{Máximo\ de\ Likelihood} \]
El Likelihood ratio da una medida más conveniente del soporte de los datos para determinado valor de probabilidades que el likelihood, ya que relativiza los valores de los likelihood al valor del máximo likelihood.
Cuanto más cerca de 1 está un Likelihood ratio significa que ese valor de p está más “sustentado” por los datos.
El LR test compara dos modelos anidados: modelo mayor vs. modelo reducido. La \(H_0\) plantea que algunos parámetros en el modelo completo son igual a 0. Este LR tiene aproximadamente una distribución chi-cuadrado bajo la hipótesis nula.
Analicemos nuestro modelo
Solamente los coeficientes que acompañan a las variables deag y decr resultaron significativos según el test de Wald. Esto es lo mismo que observamos en las curvas de KM.
Respecto de la variable fase, que tiene 3 categorías, observemos que fue transformada en una variable dummy: el modelo ha tomado como categoría de referencia “aguda” y los valores de HR son en referencia a esta categoría: “crisis blástica” respecto a “aguda” y “crónica” respecto a “aguda”.
La columna Coefficient representa los valores de \(\beta\) estimados por verosimilitud parcial. Valores positivos de \(\beta\) indican variables que contribuyen a un incremento de riesgo, en tanto que valores negativos de \(\beta\) indican variables que contribuyen a reducir el riesgo. Si miramos los HR, vemos que decr resultó un factor protector importante.
Probaremos un modelo con cuatro variables ¿Cuál saco del modelo: edad, sexo o fase? Probemos distintos modelos:
-
Modelo 2:
fase + decr + deag + edad(sacandosexo)
Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag + edad,
data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.34930 1.41808 0.54010 0.647 0.517801
fasecrónica -0.66770 0.51289 0.35813 -1.864 0.062262 .
decrsi -1.04100 0.35310 0.33283 -3.128 0.001762 **
deagsi 1.15232 3.16554 0.32110 3.589 0.000332 ***
edad -0.00272 0.99728 0.01452 -0.187 0.851418
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4181 0.7052 0.4920 4.087
fasecrónica 0.5129 1.9498 0.2542 1.035
decrsi 0.3531 2.8321 0.1839 0.678
deagsi 3.1655 0.3159 1.6870 5.940
edad 0.9973 1.0027 0.9693 1.026
Concordance= 0.758 (se = 0.031 )
Likelihood ratio test= 39.98 on 5 df, p=2e-07
Wald test = 38.28 on 5 df, p=3e-07
Score (logrank) test = 47.16 on 5 df, p=5e-09# AIC
AIC(m2)[1] 376.825-
Modelo 3:
fase + decr + deag + sexo(sacandoedad)
Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag + sexo,
data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.3378 1.4019 0.5429 0.622 0.533779
fasecrónica -0.5715 0.5647 0.3647 -1.567 0.117090
decrsi -1.0940 0.3349 0.3246 -3.370 0.000750 ***
deagsi 1.2075 3.3451 0.3240 3.726 0.000194 ***
sexoM 0.2509 1.2852 0.3251 0.772 0.440233
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4019 0.7133 0.4837 4.0631
fasecrónica 0.5647 1.7709 0.2763 1.1540
decrsi 0.3349 2.9863 0.1772 0.6326
deagsi 3.3451 0.2989 1.7725 6.3128
sexoM 1.2852 0.7781 0.6796 2.4306
Concordance= 0.762 (se = 0.03 )
Likelihood ratio test= 40.56 on 5 df, p=1e-07
Wald test = 38.19 on 5 df, p=3e-07
Score (logrank) test = 47.46 on 5 df, p=5e-09# AIC
AIC(m3)[1] 376.2529-
Modelo 4:
sexo + decr + deag + edad(sacandofase)
Call:
coxph(formula = Surv(tiempo, status) ~ decr + deag + sexo + edad,
data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
decrsi -1.3160459 0.2681937 0.3150468 -4.177 2.95e-05 ***
deagsi 1.1988240 3.3162147 0.3084393 3.887 0.000102 ***
sexoM 0.4531812 1.5733092 0.3241990 1.398 0.162158
edad 0.0003653 1.0003654 0.0142724 0.026 0.979578
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
decrsi 0.2682 3.7286 0.1446 0.4973
deagsi 3.3162 0.3015 1.8118 6.0700
sexoM 1.5733 0.6356 0.8334 2.9701
edad 1.0004 0.9996 0.9728 1.0287
Concordance= 0.732 (se = 0.032 )
Likelihood ratio test= 36.35 on 4 df, p=2e-07
Wald test = 32.6 on 4 df, p=1e-06
Score (logrank) test = 38.43 on 4 df, p=9e-08# AIC
AIC (m4)[1] 378.4578De acuerdo al criterio AIC, considerando los modelos construidos, m3 sería un mejor modelo, dado que tiene un menor AIC, pero se observa que existen términos sin significación en este modelo, según el test de Wald.
Ajustemos ahora un modelo con tres variables, partiendo de m3, cuya fórmula era:
Surv(tiempo, status) ~ fase + decr + deag + sexo
<environment: 0x00000268ef331770>En general, el criterio que se utiliza para “sacar” variables del modelo, es sacar aquellas cuyo \(\beta\) haya resultado no significativo. En el caso de m3 serían los \(\beta\) correspondientes a las variables sexo y fase.
-
Modelo 5:
fase + decr + deag(sacandosexo)
Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.3449 1.4119 0.5402 0.639 0.523100
fasecrónica -0.6509 0.5216 0.3467 -1.878 0.060440 .
decrsi -1.0597 0.3466 0.3176 -3.336 0.000849 ***
deagsi 1.1633 3.2004 0.3160 3.681 0.000232 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4119 0.7083 0.4898 4.0698
fasecrónica 0.5216 1.9173 0.2644 1.0290
decrsi 0.3466 2.8856 0.1860 0.6458
deagsi 3.2004 0.3125 1.7227 5.9456
Concordance= 0.753 (se = 0.03 )
Likelihood ratio test= 39.95 on 4 df, p=4e-08
Wald test = 38.18 on 4 df, p=1e-07
Score (logrank) test = 47.11 on 4 df, p=1e-09# AIC
AIC(m5)[1] 374.8601-
Modelo 6:
decr + deag + sexo(sacandofase)
Call:
coxph(formula = Surv(tiempo, status) ~ decr + deag + sexo, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
decrsi -1.3143 0.2687 0.3072 -4.279 1.88e-05 ***
deagsi 1.1977 3.3124 0.3051 3.925 8.66e-05 ***
sexoM 0.4555 1.5769 0.3115 1.462 0.144
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
decrsi 0.2687 3.7220 0.1472 0.4906
deagsi 3.3124 0.3019 1.8215 6.0236
sexoM 1.5769 0.6341 0.8564 2.9037
Concordance= 0.74 (se = 0.031 )
Likelihood ratio test= 36.35 on 3 df, p=6e-08
Wald test = 32.6 on 3 df, p=4e-07
Score (logrank) test = 38.43 on 3 df, p=2e-08# AIC
AIC(m6)[1] 376.4584El m5 parece ser un mejor modelo, con un AIC menor (374.8600995).
Ensayemos ahora un modelo con 2 variables, a partir entonces de m5:
Surv(tiempo, status) ~ fase + decr + deag
<environment: 0x00000268f089de38>Saco fase, dado que su coeficiente resultó no significativo.
-
Modelo 7:
deag + decr
Call:
coxph(formula = Surv(tiempo, status) ~ decr + deag, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
decrsi -1.2532 0.2856 0.3038 -4.125 3.71e-05 ***
deagsi 1.1001 3.0045 0.2959 3.717 0.000201 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
decrsi 0.2856 3.5015 0.1574 0.518
deagsi 3.0045 0.3328 1.6822 5.366
Concordance= 0.739 (se = 0.03 )
Likelihood ratio test= 34.13 on 2 df, p=4e-08
Wald test = 32.9 on 2 df, p=7e-08
Score (logrank) test = 37.62 on 2 df, p=7e-09# AIC
AIC (m7)[1] 376.6813Ahora todas las variables tienen significación y, si bien no ha habido mejora en el AIC, según los valores del test de Wald, parece un mejor modelo. No obstante, podemos comparar los modelos “candidatos”.
La comparación entre los modelos se realiza con la función anova(), que realiza la prueba de Razón de Verosimilitud entre dos modelos. Los argumentos de la función son los dos modelos ajustados a comparar. La salida de la función es una tabla en donde muestra para los dos modelos el log-verosimilitud, el estadístico Chisq, los grados de libertad Df y el p-valor P(>|Chi|) de la prueba.
Ahora, seleccionamos los dos modelos a comparar en nuestro caso: m5 y m7.
anova(m5, m7)Analysis of Deviance Table
Cox model: response is Surv(tiempo, status)
Model 1: ~ fase + decr + deag
Model 2: ~ decr + deag
loglik Chisq Df Pr(>|Chi|)
1 -183.43
2 -186.34 5.8212 2 0.05444 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Recordemos que los modelos deben ser anidados para poder hacer ANOVA. En este caso, lo que hace es comparar los log de Likelihood de ambos modelos. Esa diferencia se distribuye como un Chi cuadrado. El valor de p se encuentra en el límite de significación (considerando 0,05). Si somos estrictos, el valor de p indica que no hay diferencia entre ambos modelos, por lo tanto nos quedaríamos con el de menos variables, de acuerdo al principio de parsimonia.
En nuestro caso, podemos decidir quedarnos con el m5, dado que la fase de la enfermedad puede resultar un elemento predictivo importante. Como se indicó anteriormente, la regresión de Cox generalmente tiene fines predictivos, así que podemos ver en la bibliografía, modelos que no siguen todas las “normas” del modelado, porque se hace importante mantener variables como edad o sexo, aún cuando no resulten significativas, a fin de contar con intervalos de predicción por sexo o grupo etario.
Supongamos entonces que decidimos quedarnos con el m5, aunque rompamos algunas reglas. Interpretemos ahora los parámetros del modelo:
summary(m5)Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.3449 1.4119 0.5402 0.639 0.523100
fasecrónica -0.6509 0.5216 0.3467 -1.878 0.060440 .
decrsi -1.0597 0.3466 0.3176 -3.336 0.000849 ***
deagsi 1.1633 3.2004 0.3160 3.681 0.000232 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4119 0.7083 0.4898 4.0698
fasecrónica 0.5216 1.9173 0.2644 1.0290
decrsi 0.3466 2.8856 0.1860 0.6458
deagsi 3.2004 0.3125 1.7227 5.9456
Concordance= 0.753 (se = 0.03 )
Likelihood ratio test= 39.95 on 4 df, p=4e-08
Wald test = 38.18 on 4 df, p=1e-07
Score (logrank) test = 47.11 on 4 df, p=1e-09Para la interpretación, nos centramos en la columna exp(coef), que corresponde a los HR. Partiendo de dichos valores, podemos concluir:
El riesgo de muerte de los pacientes que padecen enfermedad injerto contra huésped aguda es aproximadamente el triple de aquellos que no la han padecido (\(HR = 3,2\)).
Los pacientes que hayan padecido enfermedad injerto contra huésped crónica tienen 0,34 veces el riesgo de morir post datos de los que no la tuvieron. Puede decirse también (y quizás quedaría mejor expresado) que tienen un 66% menos riesgo que los que no tuvieron enfermedad injerto contra huésped crónica (\(HR = 0,34\)).
Los pacientes que reciben trasplante en la fase crónica de la enfermedad, tienen un riesgo 48% menor de morir post datos que aquellos que son trasplantados en la fase aguda (si consideramos un \(p< 0,1\), este término tendría significación). Se observó un aumento de riesgo en los que reciben trasplante en la crisis blástica respecto de quienes lo reciben en la aguda, pero este término no resultó significativo.
Algunas alternativas
Como hemos visto para modelados anteriores, podemos construir el modelo de Cox con funciones del paquete stats y del paquete performance (Lüdecke et al. 2021).
Les recordamos que para la comparación de modelos con la función compare_performance() van a observar que se utiliza el indicador AIC weights en lugar del AIC. El AIC weights es un parámetro que cuantifica de manera relativa la calidad de un modelo. Refleja la probabilidad relativa de que un modelo sea el mejor entre un conjunto de modelos candidatos. Su cálculo se basa en la comparación de los valores de AIC de cada modelo considerado.
Por esto, se interpreta de manera inversa al AIC: a mayor valor de AIC weights, mayor probabilidad de que el modelo sea un mejor candidato en comparación al resto.
Les dejamos a continuación el proceso backwards utilizando funciones de estos paquetes.
Single term deletions
Model:
Surv(tiempo, status) ~ fase + decr + deag + sexo + edad
Df AIC
<none> 378.14
fase 2 378.46
decr 1 386.29
deag 1 389.22
sexo 1 376.82
edad 1 376.25Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag + edad,
data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.34930 1.41808 0.54010 0.647 0.517801
fasecrónica -0.66770 0.51289 0.35813 -1.864 0.062262 .
decrsi -1.04100 0.35310 0.33283 -3.128 0.001762 **
deagsi 1.15232 3.16554 0.32110 3.589 0.000332 ***
edad -0.00272 0.99728 0.01452 -0.187 0.851418
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4181 0.7052 0.4920 4.087
fasecrónica 0.5129 1.9498 0.2542 1.035
decrsi 0.3531 2.8321 0.1839 0.678
deagsi 3.1655 0.3159 1.6870 5.940
edad 0.9973 1.0027 0.9693 1.026
Concordance= 0.758 (se = 0.031 )
Likelihood ratio test= 39.98 on 5 df, p=2e-07
Wald test = 38.28 on 5 df, p=3e-07
Score (logrank) test = 47.16 on 5 df, p=5e-09summary(fit_m3)Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag + sexo,
data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.3378 1.4019 0.5429 0.622 0.533779
fasecrónica -0.5715 0.5647 0.3647 -1.567 0.117090
decrsi -1.0940 0.3349 0.3246 -3.370 0.000750 ***
deagsi 1.2075 3.3451 0.3240 3.726 0.000194 ***
sexoM 0.2509 1.2852 0.3251 0.772 0.440233
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4019 0.7133 0.4837 4.0631
fasecrónica 0.5647 1.7709 0.2763 1.1540
decrsi 0.3349 2.9863 0.1772 0.6326
deagsi 3.3451 0.2989 1.7725 6.3128
sexoM 1.2852 0.7781 0.6796 2.4306
Concordance= 0.762 (se = 0.03 )
Likelihood ratio test= 40.56 on 5 df, p=1e-07
Wald test = 38.19 on 5 df, p=3e-07
Score (logrank) test = 47.46 on 5 df, p=5e-09summary(fit_m4)Call:
coxph(formula = Surv(tiempo, status) ~ decr + deag + sexo + edad,
data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
decrsi -1.3160459 0.2681937 0.3150468 -4.177 2.95e-05 ***
deagsi 1.1988240 3.3162147 0.3084393 3.887 0.000102 ***
sexoM 0.4531812 1.5733092 0.3241990 1.398 0.162158
edad 0.0003653 1.0003654 0.0142724 0.026 0.979578
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
decrsi 0.2682 3.7286 0.1446 0.4973
deagsi 3.3162 0.3015 1.8118 6.0700
sexoM 1.5733 0.6356 0.8334 2.9701
edad 1.0004 0.9996 0.9728 1.0287
Concordance= 0.732 (se = 0.032 )
Likelihood ratio test= 36.35 on 4 df, p=2e-07
Wald test = 32.6 on 4 df, p=1e-06
Score (logrank) test = 38.43 on 4 df, p=9e-08# Comparación de modelos
compare_performance(m1, fit_m2, fit_m3, fit_m4,
metrics = "AIC",
rank = T)# Comparison of Model Performance Indices
Name | Model | AIC weights | Performance-Score
------------------------------------------------
fit_m3 | coxph | 0.404 | 100.00%
fit_m2 | coxph | 0.304 | 62.75%
m1 | coxph | 0.157 | 8.58%
fit_m4 | coxph | 0.134 | 0.00%## Selección a partir de fit_m3
drop1(fit_m3)Single term deletions
Model:
Surv(tiempo, status) ~ fase + decr + deag + sexo
Df AIC
<none> 376.25
fase 2 376.46
decr 1 386.02
deag 1 387.91
sexo 1 374.86Call:
coxph(formula = Surv(tiempo, status) ~ fase + decr + deag, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.3449 1.4119 0.5402 0.639 0.523100
fasecrónica -0.6509 0.5216 0.3467 -1.878 0.060440 .
decrsi -1.0597 0.3466 0.3176 -3.336 0.000849 ***
deagsi 1.1633 3.2004 0.3160 3.681 0.000232 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.4119 0.7083 0.4898 4.0698
fasecrónica 0.5216 1.9173 0.2644 1.0290
decrsi 0.3466 2.8856 0.1860 0.6458
deagsi 3.2004 0.3125 1.7227 5.9456
Concordance= 0.753 (se = 0.03 )
Likelihood ratio test= 39.95 on 4 df, p=4e-08
Wald test = 38.18 on 4 df, p=1e-07
Score (logrank) test = 47.11 on 4 df, p=1e-09summary(fit_m6)Call:
coxph(formula = Surv(tiempo, status) ~ decr + deag + sexo, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
decrsi -1.3143 0.2687 0.3072 -4.279 1.88e-05 ***
deagsi 1.1977 3.3124 0.3051 3.925 8.66e-05 ***
sexoM 0.4555 1.5769 0.3115 1.462 0.144
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
decrsi 0.2687 3.7220 0.1472 0.4906
deagsi 3.3124 0.3019 1.8215 6.0236
sexoM 1.5769 0.6341 0.8564 2.9037
Concordance= 0.74 (se = 0.031 )
Likelihood ratio test= 36.35 on 3 df, p=6e-08
Wald test = 32.6 on 3 df, p=4e-07
Score (logrank) test = 38.43 on 3 df, p=2e-08# Comparación de modelos
compare_performance(fit_m3, fit_m5, fit_m6,
metrics = "AIC",
rank = T)# Comparison of Model Performance Indices
Name | Model | AIC weights | Performance-Score
------------------------------------------------
fit_m5 | coxph | 0.513 | 100.00%
fit_m3 | coxph | 0.256 | 8.85%
fit_m6 | coxph | 0.231 | 0.00%## Selección a partir de fit_m5
drop1(fit_m5)Single term deletions
Model:
Surv(tiempo, status) ~ fase + decr + deag
Df AIC
<none> 374.86
fase 2 376.68
decr 1 384.27
deag 1 386.00Call:
coxph(formula = Surv(tiempo, status) ~ decr + deag, data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
decrsi -1.2532 0.2856 0.3038 -4.125 3.71e-05 ***
deagsi 1.1001 3.0045 0.2959 3.717 0.000201 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
decrsi 0.2856 3.5015 0.1574 0.518
deagsi 3.0045 0.3328 1.6822 5.366
Concordance= 0.739 (se = 0.03 )
Likelihood ratio test= 34.13 on 2 df, p=4e-08
Wald test = 32.9 on 2 df, p=7e-08
Score (logrank) test = 37.62 on 2 df, p=7e-09# Comparación de modelos
compare_performance(fit_m5, fit_m7,
metrics = "AIC",
rank = T)# Comparison of Model Performance Indices
Name | Model | AIC weights | Performance-Score
------------------------------------------------
fit_m5 | coxph | 0.713 | 100.00%
fit_m7 | coxph | 0.287 | 0.00%Por otro lado, recordemos que R permite también hacer una selección automática de los modelos, tanto para supervivencia como para cualquier tipo de modelado. Normalmente la bibliografía no recomienda los procedimientos automáticos, pero tengamos en claro lo que ocurre en cada caso:
“hacia atrás / adelante” (el valor por defecto): la selección comienza con el modelo completo y elimina los predictores uno a la vez, en cada paso, considerando si el criterio será mejorado agregando de nuevo una variable eliminada en un paso anterior.
“hacia adelante / hacia atrás”, la selección comienza con un modelo que incluye sólo una constante, y añade predictores uno a la vez, en cada paso considerando si el criterio se mejorará mediante la eliminación de una variable agregada anteriormente.
“atrás” y “adelante” son similares sin la reconsideración en cada paso.
Predicción de la curva de supervivencia
Ahora, estaríamos en condiciones de obtener la función de supervivencia ajustada mediante el modelo de Cox seleccionado. La función survfit() del paquete survival calcula la función de supervivencia pronosticada para un modelo de riesgos proporcionales de Cox.
Para ello, la función de R es:
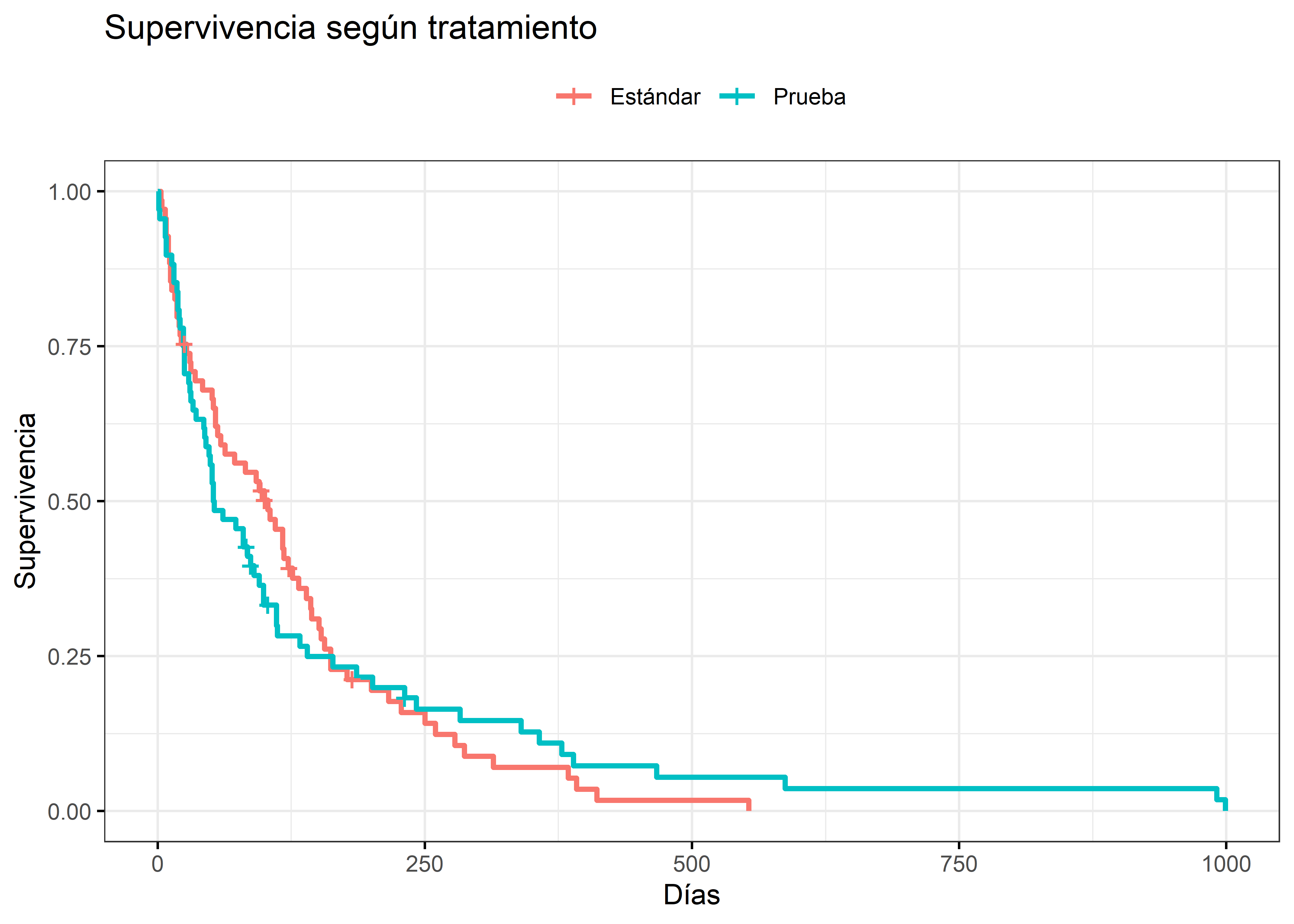
Podríamos comparar esto con lo obtenido en la estimación de Kaplan-Meier (ver módulo de KM). Pero, siempre resulta más claro realizar la comparación en forma gráfica: graficaremos la función de supervivencia obtenida mediante el estimador de Kaplan-Meier y la obtenida mediante el modelo de Cox seleccionado. Para esto, primero tendremos que crear una lista con las funciones de supervivencia requeridas para luego graficarlas utilizando la función ggsurvplot_combine() del paquete survminer (Kassambara, Kosinski, y Biecek 2024).
# Creamos un objeto con la estimación de KM
global <- Surv(datos$tiempo, datos$status)
# Creamos una lista con la función de supervivencia del modelo final
# seleccionado y la función del estimador de KM
fit <- list(modelo = survfit(m5),
global = survfit(global ~ 1))
# Generamos las curvas de supervivencia
ggsurvplot_combine(fit,
data = datos,
ggtheme = theme_bw(),
title = "Comparación del ajuste del modelo de Cox y el estimador de KM",
xlab = "Días",
ylab = "Supervivencia",
legend.title = "",
legend.labs = c("Ajuste por Cox", "Estimador de KM")
)
Podemos observar que el modelo seleccionado, ajusta bastante bien (sobreestima al principio, subestima al final). Sin embargo, en lo que a modelado respecta, para evaluar la calidad de ajuste contamos con parámetros adicionales.
Calidad de ajuste de un modelo
Hay pocas medidas para evaluar el ajuste de un modelo de supervivencia. Una de las más simples es \(R^2\), cuya expresión es: \[ R^2_{LR}= 1- \bigg(\frac{Likelihood(modelo\ nulo)}{Likelihood(modelo\ ajustado)} \bigg )^ \frac{2}{n} \]
Su interpretación es similar a la del \(R^2\) de los otros modelos lineales:
\(R^2\) puede ser interpretado como el poder explicativo de las covariables en el tiempo de ocurrencia del evento en estudio.
\(R^2\) tiene valores bajos en los análisis de supervivencia (alrededor de 30% de poder explicativo), por lo que muchos autores no lo consideran apropiado. De hecho, en las salidas de R de los modelos, observamos que no lo muestra actualmente, siendo que antes sí lo ofrecía, atendiendo a estas y otras cuestiones teóricas. En su lugar, ofrece el valor de concordancia. Profundizaremos un poco sobre este concepto, ya que no lo hemos visto en otros modelos.
El uso de la estadística de concordancia para los modelos de Cox fue popularizado por Harrel (Harrell, Lee, y Mark 1996), y ahora es la medida más usada como bondad de ajuste en los modelos de supervivencia. Una ventaja de la estadística es que está bien definida, no solo para los modelos de supervivencia, sino también para la regresión lineal logística y ordinaria.
En general, si \(yi\) y \(xi\) son los valores observados y predichos por el modelo, respectivamente, la concordancia se define como \(P(x_i > x_j|y_i> y_j)\), la probabilidad de que la predicción \(x\) vaya en la misma dirección que los datos reales \(y\). Un par de las observaciones \(i, j\) se consideran concordantes si la predicción y los datos van en la misma dirección. La concordancia es la fracción de pares concordantes.
En general, se acepta la siguiente escala:
| Concordancia (c) | Poder discriminatorio |
|---|---|
| 0.3 < c < 0.4 | Bajo |
| c = 0.5 | Por azar |
| 0.6 < c < 0.7 | Común |
| 0.7 < c < 0.8 | Muy bueno |
| 0.8 < c < 0.9 | Excelente |
Si observamos, el valor de concordancia para el modelo m5 (0.753), lo que indica muy buena concordancia entre lo observado y lo predicho por el modelo.
Análisis de residuos
Como ustedes recordarán, se denomina residuo a la diferencia entre el valor observado y el valor estimado por la ecuación de regresión, es decir a lo que la ecuación de regresión deja sin explicar para cada observación.
La definición de residuo en el análisis de supervivencia no es tan simple y directa como esta definición, dado, que, por ejemplo, un residuo obtenido como respuesta observada menos esperada, no tiene en consideración el tiempo observado de un individuo censurado.
En el análisis de supervivencia, se describen distintos tipos de residuos que sirven para evaluar distintos aspectos del modelo:
| Evaluación | Tipo de residuo |
|---|---|
| Verificar riesgos proporcionales | Residuos de Schoenfeld |
| Evaluar si es adecuado incluir las variables en forma lineal en el modelo | Residuos Martingale |
| Detectar residuos grandes (outliers) | Residuos de Deviance |
| Impacto que tiene cada observación en el modelo, tanto en forma global como por variable | Residuos Score |
Y ahora algo más… para covariables con pocas categorías, las curvas de KM estratificadas dan una idea si se cumple el presupuesto de riesgos proporcionales de Cox. Curvas que son razonablemente paralelas a lo largo del tiempo indican proporcionalidad de riesgo entre las categorías y, por el contrario, el entrecruzamiento o una variación en las distancias entre las categorías, podría indicar falta de proporcionalidad.
Si tienen presentes las curvas de KM que construimos para este ejemplo, en todas las curvas que se muestran, parece razonable suponer que se cumple el supuesto de proporcionalidad, aún en el caso de la variable sexo, dado que ambas categorías están prácticamente superpuestas, separándose recién al final, cuando quedan pocas observaciones.
A continuación, abordaremos el análisis de residuos, al menos de algunos de ellos. Para el desarrollo de gráficos seguiremos explorando el paquete survminer. Les aclaramos, además, que no utilizaremos la función check_model() del paquete performance para esta ocasión dado que no permite aún el análisis de residuales para modelos de Cox.
Residuos de Schoenfeld
Podríamos preguntarnos si el efecto de cada covariable será el mismo a medida que transcurra el tiempo, porque si no es así, se trataría de covariables tiempo dependientes. Para responder esta cuestión, se calculan los Residuos de Schoenfeld.
Se genera un residuo para cada variable y para cada paciente, es decir que si tenemos un modelo de Cox con tres factores pronóstico se calcularán 3 residuos de Schoenfeld por paciente. Estos residuos valen cero para las observaciones incompletas. Es posible modificar estos residuos con el fin de que no valgan cero para las observaciones incompletas, obteniéndose entonces los denominados residuos Schoenfeld corregidos o escalados.
En R, la función cox.zph() realiza la prueba de hipótesis de correlación para los residuos de Schoenfeld de cada covariable con alguna transformación del tiempo, los argumentos de la función son:
fit: Un objeto coxph resultado de un ajuste del modelo de regresión de Cox.transform: Tipo de transformación del tiempo, posibles valores son"km","rank","identity"o una función.global: una prueba chi cuadrado global.
La salida de la función es una tabla en donde para cada covariable calcula el coeficiente \(rho\), el estadístico de prueba chisq y su respectivo p-valor, además incluye una prueba global. Por ejemplo, para el m5 o para m7, el supuesto de riesgos proporcionales puede ser verificado mediante el contraste de hipótesis generado mediante el comando:
cox.zph(m5,
transform = "km",
global = TRUE) chisq df p
fase 9.308 2 0.00952
decr 7.834 1 0.00513
deag 0.279 1 0.59742
GLOBAL 18.546 4 0.00097¿Qué significa esta salida?
La \(H_0\) que se testea es que la correlación lineal entre el residuo de Schoenfeld y el tiempo de supervivencia es cero.
Esto es equivalente a probar \(H_0\): pendiente igual a cero o $H_0: logHR$ es constante en el tiempo.
De lo expuesto se concluye que existe evidencia significativa al 5% de que se viole el supuesto de riesgos proporcionales, desde el punto de vista global, y para las covariables decr y fase.
La validación del supuesto de riesgos proporcionales puede realizarse también en forma gráfica con la función ggcoxdiagnostics():
ggcoxdiagnostics(m5,
type = "schoenfeld",
title = "Residuos de Schonfeld",
ylab = "Residuos",
xlab = "Tiempo")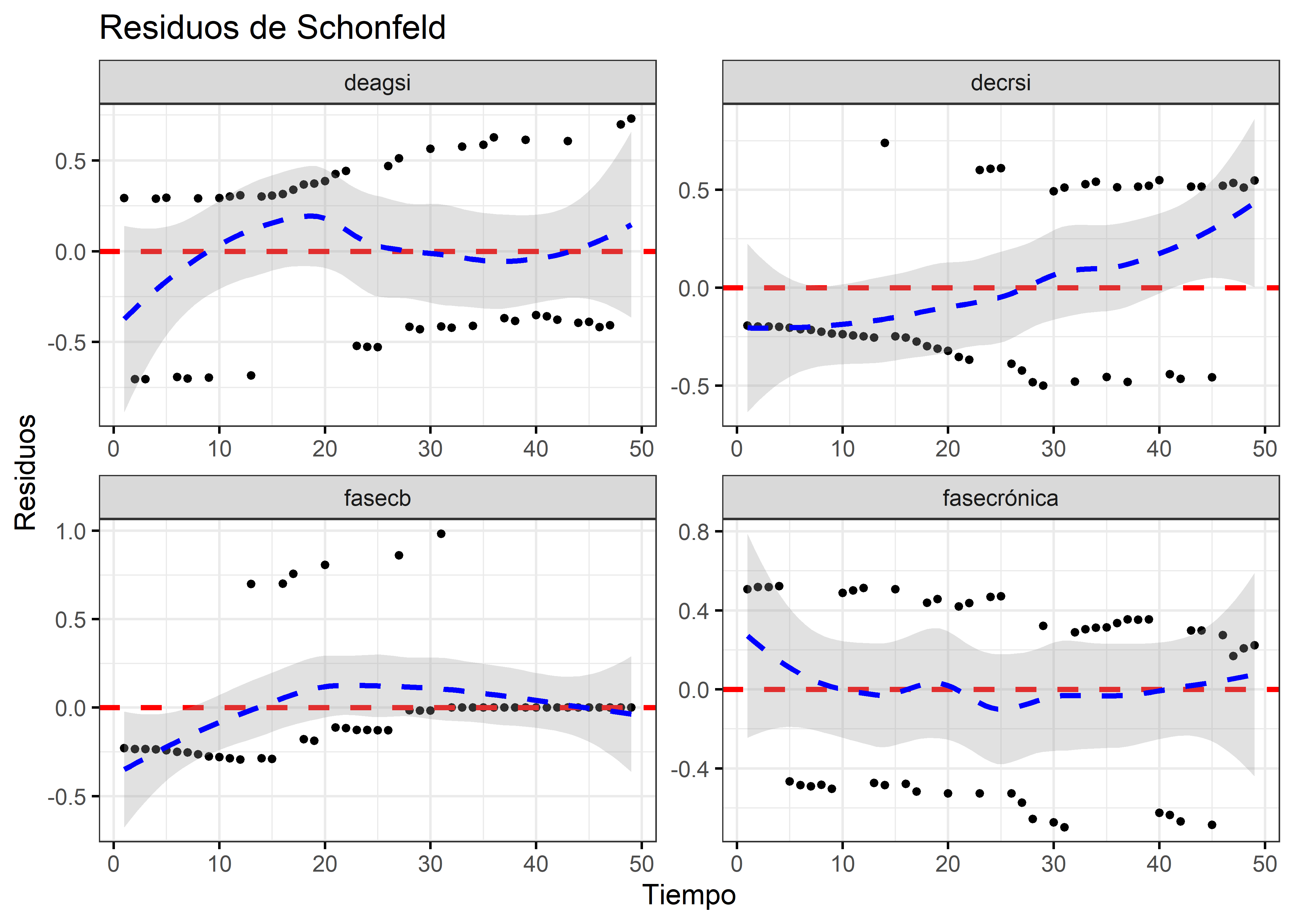
La interpretación se facilita con el agregado de una línea de tendencia “lowess”, de esta forma, cuando esta línea se desvía de una línea constante, se sospecha una estructura tiempo dependiente en el efecto de la covariable.
Los gráficos confirman lo que hallamos con el test: los residuos tienen un patrón o estructura con el tiempo. En el caso de la variable decr, parece visualizarse una relación lineal, lo mismo en fase:cb.
Frente al problema de No proporcionalidad, se deberá evaluar:
Magnitud
Puntos influyentes
¿Cuáles son las posibles soluciones? Estratificar por covariable dependiente del tiempo, dividir el eje del tiempo o utilizar otro tipo de modelo.
Continuaremos analizando los residuos de este modelo y retomaremos el tema cuando lleguemos a modelos estratificados.
Residuos Martingale
El residuo Martingale de un sujeto es simplemente la diferencia entre el número de acontecimientos observados y el número de acontecimientos esperados según el modelo.
Se grafica: Mi vs índice de individuo, permitiendo revelar sujetos mal ajustados por el modelo. Nuevamente nos será de utilidad la función ggcoxdiagnostics():
ggcoxdiagnostics(m5,
type = "martingale",
title = "Residuos de Martingale",
ylab = "Residuos",
xlab = "Índice"
)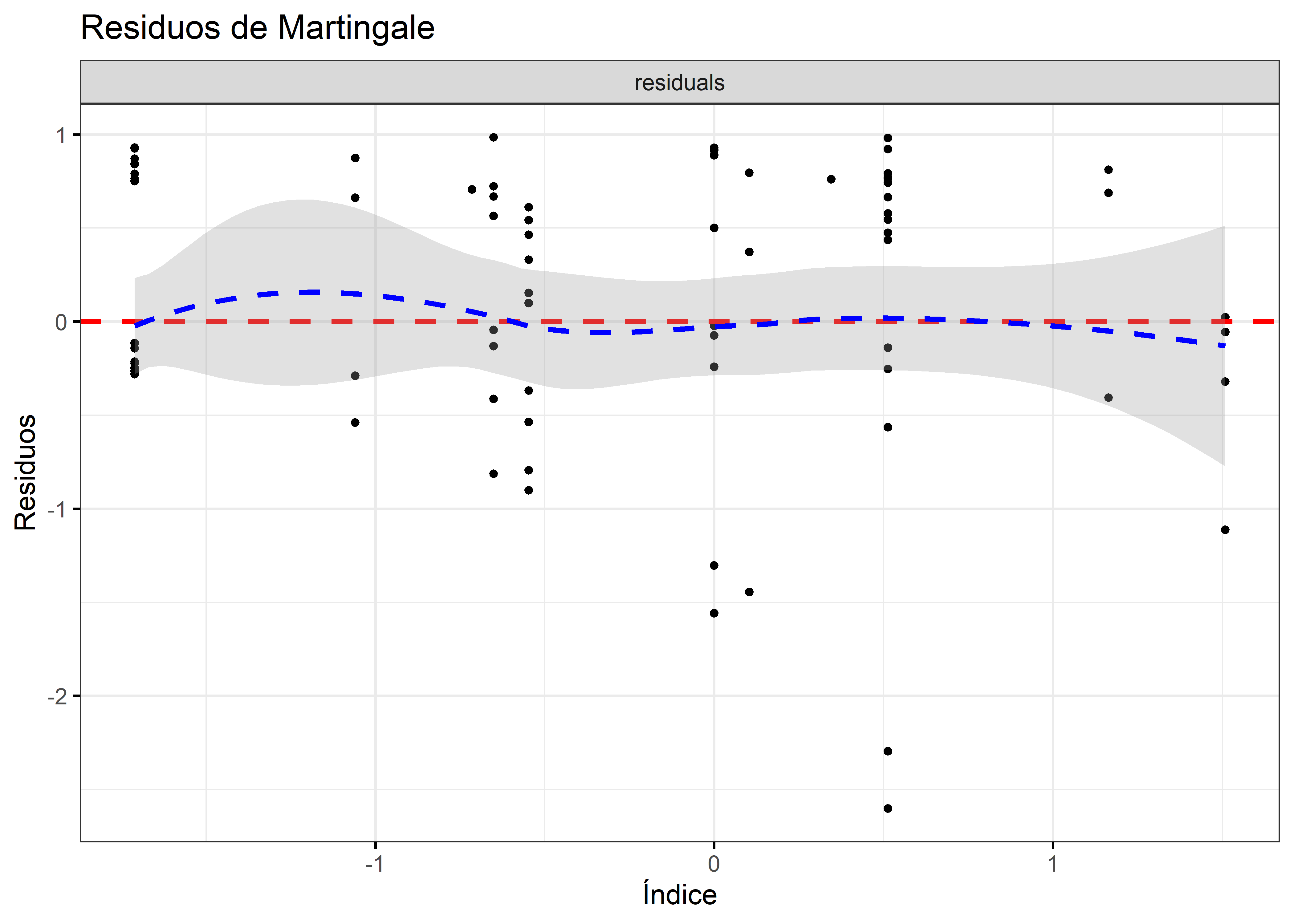
Este gráfico sirve para evidenciar posibles valores aberrantes: individuos que demoraron mucho o demasiado poco en tener el evento (como los que señalan las flechas). Se espera que se distribuyan en torno a la línea punteada del 0, sin ningún patrón remanente. Valores de Mi mayores que 0, indica que el numero de eventos observados es menor que los estimados por el modelo y viceversa.
Modelo de Cox estratificado
En algunas situaciones no podemos asumir que el riesgo basal \(h_o(t)\) sea el mismo para todos los individuos del estudio. Esto podría ser por la característica propia de la variable (como la edad) o porque el diseño sea estratificado a priori (por ej. estadíos de una enfermedad). En estos casos, los distintos \(h_o(t)\) definen los distintos estratos.
Los coeficientes \(\beta\) también se estiman por el método de verosimilitud parcial, pero los individuos en riesgo que participan de la estimación son sólo los del estrato.
El modelo de Cox estratificado constituye una de las maneras de corregir el modelo de Cox cuando no se cumple el supuesto de riesgos proporcionales para alguna de las covariables. En este caso suele correrse el modelo estratificando por la covariable que no cumple con el supuesto de riesgo proporcional. Este procedimiento permite corregir el sesgo en la estimación del parámetro, que puede presentarse cuando se viola el supuesto de riesgo proporcional. Sin embargo, presenta una desventaja y es que no existe ningún \(\beta\) que permita estimar el efecto de la covariable de estratificación.
Continuando con nuestro ejemplo, vimos que la variable decr violaba el supuesto de proporcionalidad. Deberíamos entonces usar un modelo de Cox estratificado, donde decr sea la variable de estratificación.
Call:
coxph(formula = Surv(tiempo, status) ~ fase + deag + strata(decr),
data = datos)
n= 96, number of events= 49
coef exp(coef) se(coef) z Pr(>|z|)
fasecb 0.09209 1.09647 0.54271 0.170 0.865250
fasecrónica -0.72569 0.48399 0.35111 -2.067 0.038747 *
deagsi 1.12109 3.06819 0.32007 3.503 0.000461 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
fasecb 1.096 0.9120 0.3785 3.1765
fasecrónica 0.484 2.0662 0.2432 0.9632
deagsi 3.068 0.3259 1.6385 5.7454
Concordance= 0.646 (se = 0.041 )
Likelihood ratio test= 17.02 on 3 df, p=7e-04
Wald test = 17.36 on 3 df, p=6e-04
Score (logrank) test = 18.52 on 3 df, p=3e-04Podemos nuevamente chequear la proporcionalidad en este nuevo modelo:
cox.zph(m5st,
transform="km",
global=TRUE) chisq df p
fase 10.848 2 0.0044
deag 0.448 1 0.5031
GLOBAL 11.084 3 0.0113Vemos que el modelo de Cox estratificado tampoco resuelve el problema.
Modelo de Cox extendido
El modelo de Cox que vimos inicialmente asume que las covariables no varían en el transcurso del tiempo. Pero sabemos que esto no siempre es así.
¿Cómo analizar la supervivencia cuando las covariables cambian con el tiempo, como edad, tratamiento o hábitos alimentarios?
El modelo de Cox extendido aborda esta situación mediante un proceso de conteo. Tiene las mismas premisas del modelo de Cox
\[ h(t|x(t))= h_0(t)exp(x(t)\beta) \] ¿Cuál es la diferencia? La primer diferencia está ya en la base de datos: tendremos más de una fila por individuo, dado que los valores de una variable para el mismo individuo cambian con el correr del tiempo.
Análisis de supervivencia más complejos
Hasta ahora, vimos modelos de supervivencia adecuados para tratar problemas en los cuales el evento ocurre una única vez. Pero existen situaciones en lo que esto no es así y podríamos estar interesados en eventos que pueden acontecer más de una vez para un mismo individuo, como: infartos, gestaciones, fracturas, internaciones, etc. Así también nos podrían interesar situaciones en las que existen diferentes tipos de eventos derivados de un mismo factor de riesgo en el estudio: efectos adversos por medicamentos, enfermedades oportunistas en SIDA, etc. Este análisis se conoce como Supervivencia de eventos múltiples.
El análisis de eventos múltiples, pretende responder a dos preguntas básicas:
¿Cuáles son los factores de riesgo asociados a los tiempos de diferentes eventos en un mismo individuo?
¿Cómo analizar diferentes eventos como desenlace de una misma situación de riesgo?
Las principales características de este tipo de análisis son:
Tener más de un tiempo de supervivencia por individuo.
Los individuos pueden mantenerse en el grupo de riesgo aún después de la ocurrencia de algún evento.
Dado que los intervalos de tiempo no son independientes entre sí, la utilización directa del modelo de Cox no sirve. A su vez, no tener independencia entre las observaciones puede generar error en las estimaciones.
Las estrategias para resolver estas situaciones son varias:
Ajustar un modelo de regresión en el que la variable respuesta es el número de eventos por paciente durante el período de estudio: Poisson
Utilizar Cox considerando uno de los eventos: tiempo hasta el primer evento
Utilizar Modelos multinivel
Utilizar Modelos marginales
A continuación presentaremos una clasificación de eventos múltiples, la cual no es rígida ni definitiva, dado que la evolución de métodos en esta área es grande y van surgiendo nuevos modelos, que se adecúan mejor a las situaciones analizadas.
Eventos Competitivos: sólo es posible observar tiempo hasta un evento primero que impide que otro tenga lugar. Ej; muerte x diferentes causas y un mismo factor de riesgo
Eventos Paralelos: la ocurrencia de un evento no excluye la aparición de otros eventos y no existe orden preferencial (Enfermedades oportunistas, los efectos secundarios, la pérdida de dientes)
Eventos Ordenados: la sucesión de tiempos sigue obligatoriamente un orden. Ej: IAM El riesgo subyacente cambia a medida que el individuo sufre nuevos eventos, es decir, los eventos, además de ordenarse en el tiempo, se ordenan según el riesgo basal.
Como podrán intuir el análisis se complejiza aún más, por lo cual no los abordaremos en este curso. Solamente hemos presentado los lineamientos, para que ustedes sean capaces de reconocer situaciones donde se deben aplicar estas metodologías, con el fin de que no cometan errores metodológicos importantes en el futuro (al menos referidos a estos temas).
Consideraciones sobre el tamaño de la muestra
Como ya hemos visto en la primera unidad, para determinar el tamaño de muestra necesario para un estudio, tendremos que tener una idea de la magnitud del efecto que deseamos detectar. En el análisis de supervivencia, el efecto es el HR, por ejemplo, a los 5 años, a los 10 años o al intervalo de tiempo que se desee.
Supongamos que deseamos saber si existen diferencias entre dos terapias diferentes A y B utilizadas habitualmente para tratar un determinado tipo de cáncer. Para ello se planea realizar un estudio de supervivencia. ¿Cuántos pacientes deberán estudiarse con cada tratamiento si se desea calcular el riesgo relativo con una precisión del 50% de su valor real y una seguridad del 95%? De experiencias previas, se estima que el valor real del riesgo relativo es aproximadamente igual a 3 y la probabilidad de fallecer entre los pacientes tratados con el tratamiento A de un 20%.
En este caso, para conocer si el tratamiento A tiene un efecto beneficioso sobre la evolución de los enfermos, podremos utilizar un modelo de regresión de Cox en el que se ajuste por la variable tratamiento, y a partir de cuyos coeficientes podremos estimar el HR asociado a la terapia recibida. Si, con este procedimiento, deseamos calcular el tamaño muestral mínimo necesario para detectar un determinado HR, deberemos conocer:
Una idea del valor aproximado del riesgo relativo que se desea detectar (HR).
La proporción de expuestos al factor de estudio (p), es decir, en nuestro caso, la proporción de enfermos habitualmente tratados con la terapia A.
El porcentaje de observaciones censuradas que se espera en el total de la muestra (%C)
El nivel de confianza o seguridad con el que se desea trabajar \(\alpha\)
El poder que se quiere para el estudio \(1-\beta\)
Con estos datos, el cálculo del tamaño muestral puede abordarse mediante la fórmula:
\[ n= \frac{(z_{1-\alpha/2}+z_{1+\beta})^2}{(log(HR))^2*(1-\%C)*(1-p)*p} \]
Ejemplo
Supongamos que el tratamiento (A) suele aplicarse a un 70% de los pacientes que padecen ese tipo de cáncer, mientras que la otra terapia (B) es recibida sólo por un 30% de los enfermos. Si el efecto pronóstico del tratamiento recibido va a analizarse de modo univariado, la ecuación puede aplicarse para calcular el número necesario de pacientes a estudiar. Así, para detectar un riesgo relativo de 3, suponiendo un 20% de censura y trabajando con un \(\alpha= 95\%\) y un poder del 80% se tendría:
\[ n= \frac{(1.96+0.842)^2}{(log3)^2*(1-0.2)*(1-0.7)*0.7}= 47 \]
Necesitaríamos 47 pacientes para detectar un HR de 3. A menor HR, mayor tamaño de muestra.
Si ahora deseamos usar un modelo de Cox con más variables, el tratar de ajustar un modelo más complejo con el mismo número de pacientes llevará consigo una pérdida de precisión en la estimación de los coeficientes y, con ello, del HR asociado a cada una de las variables incluidas en el modelo multivariante. En esta situación, es obvio, que se necesita realizar alguna corrección en la ecuación que permita adaptar el tamaño muestral calculado a las variables que se incluirán a posteriori en el modelo.
\[ n= \frac{(z_{1-\alpha/2}+z_{1+\beta})^2}{(logHR)^2*(1-\%C)*(1-p)*p}*\frac {1}{1-\rho^2} \]
El término agregado se lo llama factor de inflación de la varianza, donde \(\rho\) denota al coeficiente de correlación de Pearson entre el factor en estudio y aquella otra variable que incluiremos en el modelo. En el caso en el que se ajuste por más de otro factor en el modelo, lo más sencillo es considerar como el mayor coeficiente de correlación entre el factor de estudio y todas las variables incluidas. Este coeficiente de correlación, cuanto mayor sea, más incrementará el valor del factor de inflación de la varianza y, por tanto, se incrementará el tamaño de la muestra a estudiar.
Siguiendo con el ejemplo, posiblemente el tratamiento aplicado a cada enfermo dependerá de las características clínicas particulares del mismo, y recibirá una u otra terapia en función, por ejemplo, del estadío del tumor. En términos estadísticos, podrá entonces decirse que el factor tratamiento se encuentra “correlacionado” con esta característica. Supongamos, por ejemplo, que la correlación existente entre el nuevo tratamiento y el estadío del tumor es de 0,25. Este dato lo podremos obtener a partir de un estudio piloto o de otros trabajos sobre el tema. En caso de desconocerse, deberemos asumir una correlación suficientemente alta para así asegurar un poder suficiente.
El cálculo del tamaño muestral, por tanto, permite al investigador precisar el número de pacientes a estudiar para detectar como significativos efectos de una magnitud determinada. El no hacerlo, o el no conocer cuántos pacientes necesitamos para detectar un efecto como significativo podría llevarnos a cometer un error de tipo II, es decir, no encontrar diferencias cuando sí las hay.
Referencias
Cox, D. R. 1972. «Regression Models and Life-Tables». Journal of the Royal Statistical Society Series B: Statistical Methodology 34 (2): 187-202. https://doi.org/10.1111/j.2517-6161.1972.tb00899.x.
Harrell, Frank E., Kerry L. Lee, y Daniel B. Mark. 1996. «MULTIVARIABLE PROGNOSTIC MODELS: ISSUES IN DEVELOPING MODELS, EVALUATING ASSUMPTIONS AND ADEQUACY, AND MEASURING AND REDUCING ERRORS». Statistics in Medicine 15 (4): 361-87. https://doi.org/10.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM168>3.0.CO;2-4.
Hernández-Ávila, Mauricio. 2011. Epidemiología: diseño y análisis de estudios. Buenos Aires: Editorial Médica Panamericana.
Kassambara, Alboukadel, Marcin Kosinski, y Przemyslaw Biecek. 2024. «survminer: Drawing Survival Curves using ’ggplot2’». https://CRAN.R-project.org/package=survminer.
Lüdecke, Daniel, Mattan S. Ben-Shachar, Indrajeet Patil, Philip Waggoner, y Dominique Makowski. 2021. «performance: An R Package for Assessment, Comparison and Testing of Statistical Models» 6: 3139. https://doi.org/10.21105/joss.03139.
Royo-Bordonada, Miguel Angel, Javier Damian, Beatriz Perez-Gomez, Fernando Rodríguez-Artalejo, Fernando Villar Alvarez, Gonzalo Lopez-Abente, Iñaki Imaz-Iglesia, et al. 2009. Método epidemiológico. Instituto de Salud Carlos III (ISCIII). Escuela Nacional de Sanidad (ENS). http://hdl.handle.net/20.500.12105/5271.
Therneau, Terry M., y Patricia M. Grambsch. 2000. Modeling Survival Data: Extending the Cox Model. Statistics for Biology y Health. New York, NY: Springer New York. https://doi.org/10.1007/978-1-4757-3294-8.
Woodward, M. 2005. Epidemiology: Study Design and Data Analysis. Texts en statistical science. Chapman & Hall/CRC. https://books.google.com.ar/books?id=kcDHxgEACAAJ.