Semana | Tema |
|---|---|
30 oct. al 03 nov. 2024 | - Introducción a los Paquetes y Lenguajes Estadístico. Diferencias entre interfaces gráficas (GUI) y de línea de comandos (CLI). Comparativa entre software privativo y gratuito/open source. |
- R y R-Commander. Navegación del menú. Lectura e importación de archivos de datos. Estadística descriptiva. Agrupamiento de variables. Manejo de factores. Guardado de scripts y resultados. Paquetes y plugins. | |
06 al 09 nov. 2024 | - Relación entre variables numéricas. Covarianza y representación gráfica. Limitaciones. Correlación de Pearson: interpretación del signo y la magnitud.Visualización con correlogramas. Métodos no paramétricos: correlación de Spearman y de Kendall. |
- Introducción al Modelado Estadístico. Modelo lineal general: concepto y supuestos. Bondad de ajuste y análisis de residuos. Regresión lineal simple y análisis de la varianza (ANOVA). Interpretación de los resultados. | |
13 al 16 nov. 2024 | - Regresión Lineal Múltiple. Selección de variables explicativas y control de multicolinealidad. Análisis e interpretación de residuos. |
- Confusión e Interacción. Identificación y roles de las covariables. Control y detección de la confusión. Interpretación de resultados en presencia de interacción. |
Módulo VI: Análisis Epidemiológico Avanzado
Docentes: Tamara Ricardo, Christian Ballejo
Programa de Maestría en Epidemiología para la Salud Pública

Ejemplo covarianza positiva: actividad física y salud cardiovascular
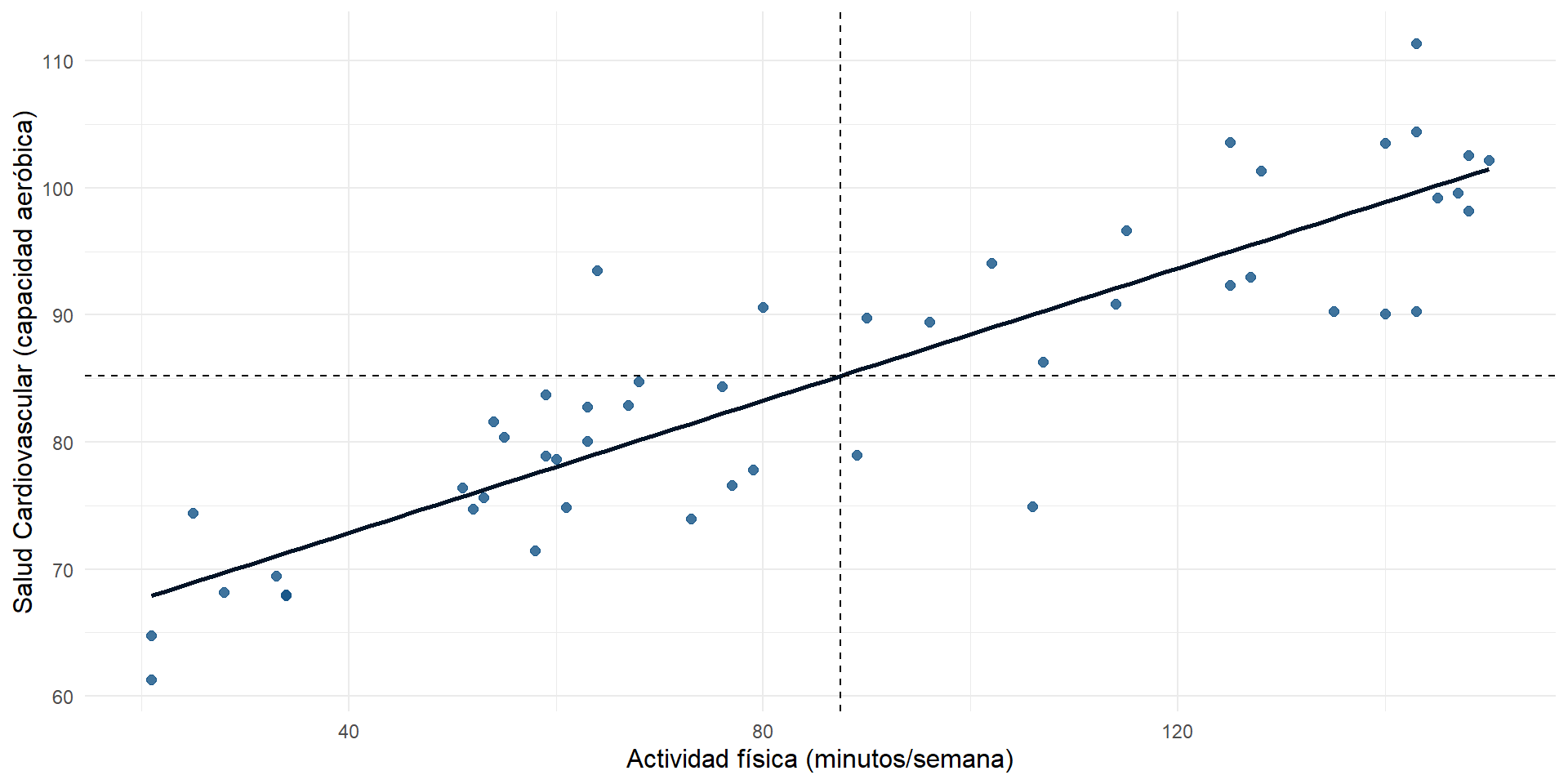
Cuando crece \(X\) (minutos de actividad física semanal) también crece \(Y\) (capacidad aeróbica), casi todos los puntos pertenecen a los cuadrantes primero y tercero.
Ejemplo covarianza negativa: consumo de alcohol y salud hepática
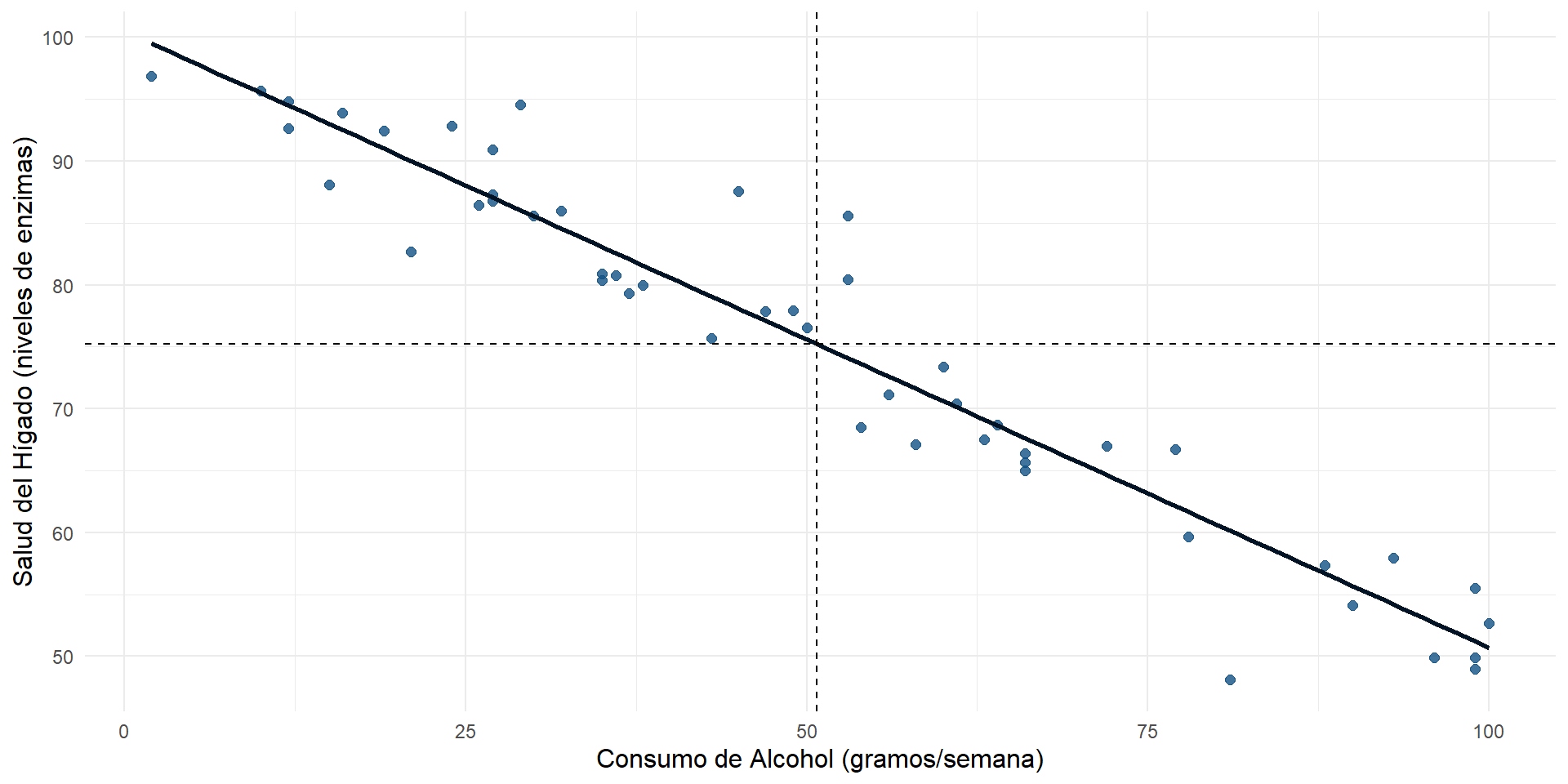
Cuando crece \(X\) (gramos alcohol por semana) decrece \(Y\) (enzimas hepáticas), casi todos los puntos pertenecen a los cuadrantes segundo y cuarto.
Ejemplo covarianza cercana a cero: horas de sueño y colesterol en sangre
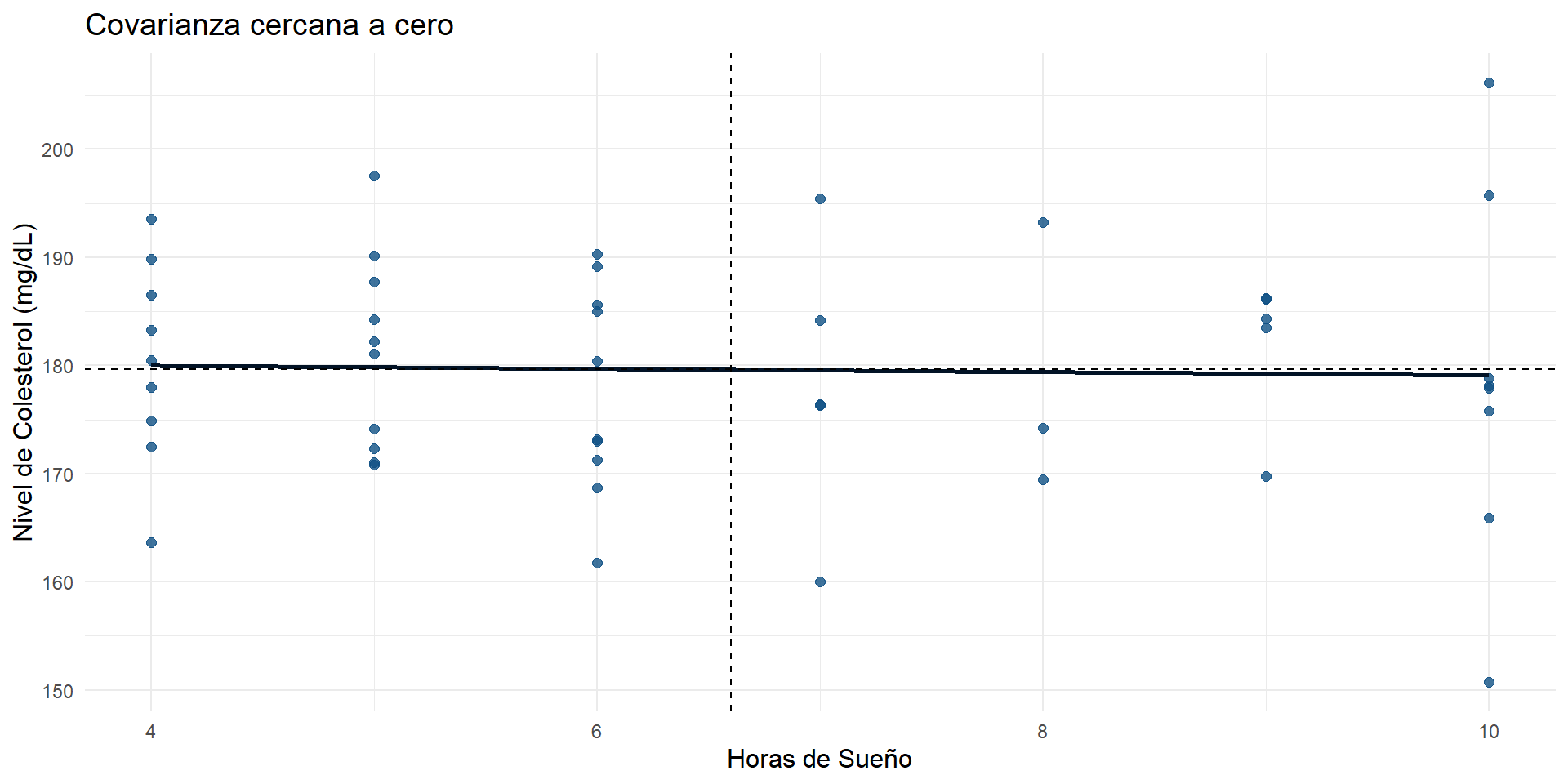
No se observa un patrón claro de dispersión entre \(X\) (horas de sueño) e \(Y\) (niveles de colesterol).
Ejemplo en R Commander
Activar R Commander (
library(Rcmdr)) y el pluginKMggplot2![]()
Importar datos desde
Datos > Importar datos> desde archivos de texto, portapapeles o URL...![]()
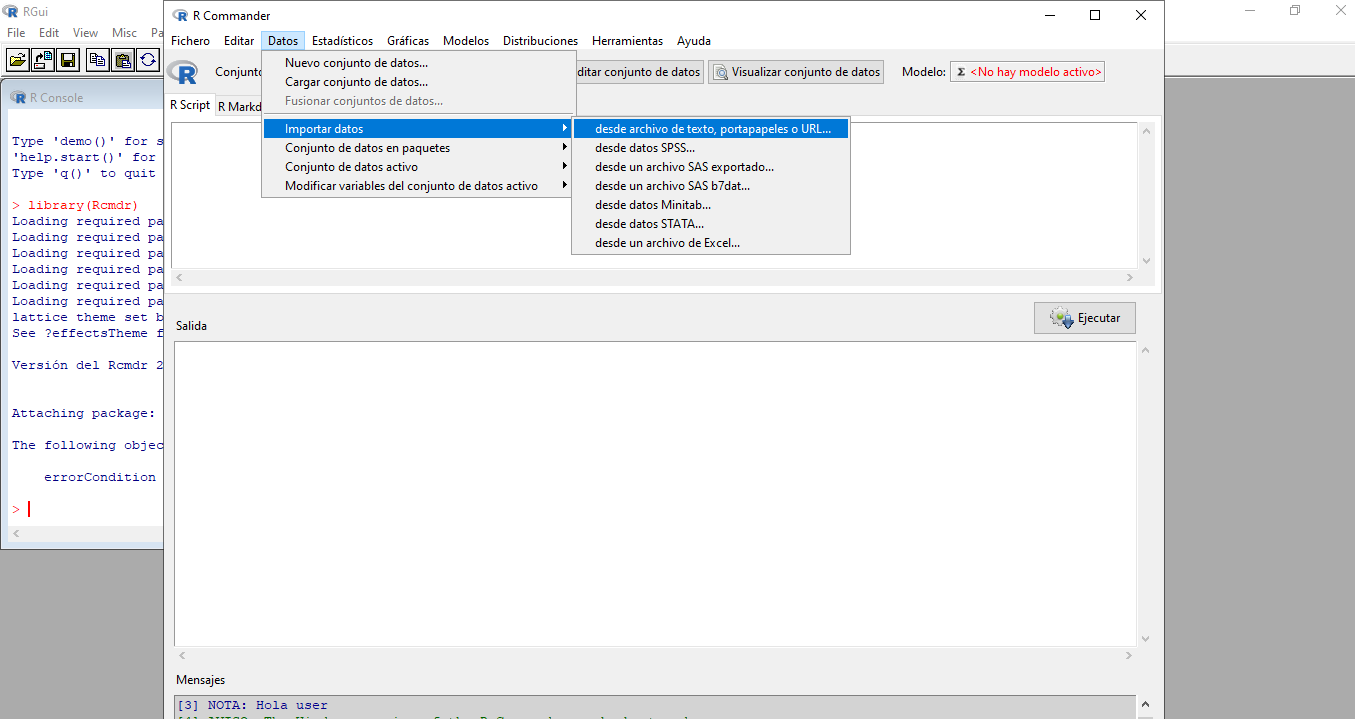
Seleccionamos las opciones
Separador de campos: punto y coma [;]ySeparador decimal: coma [,].![]()
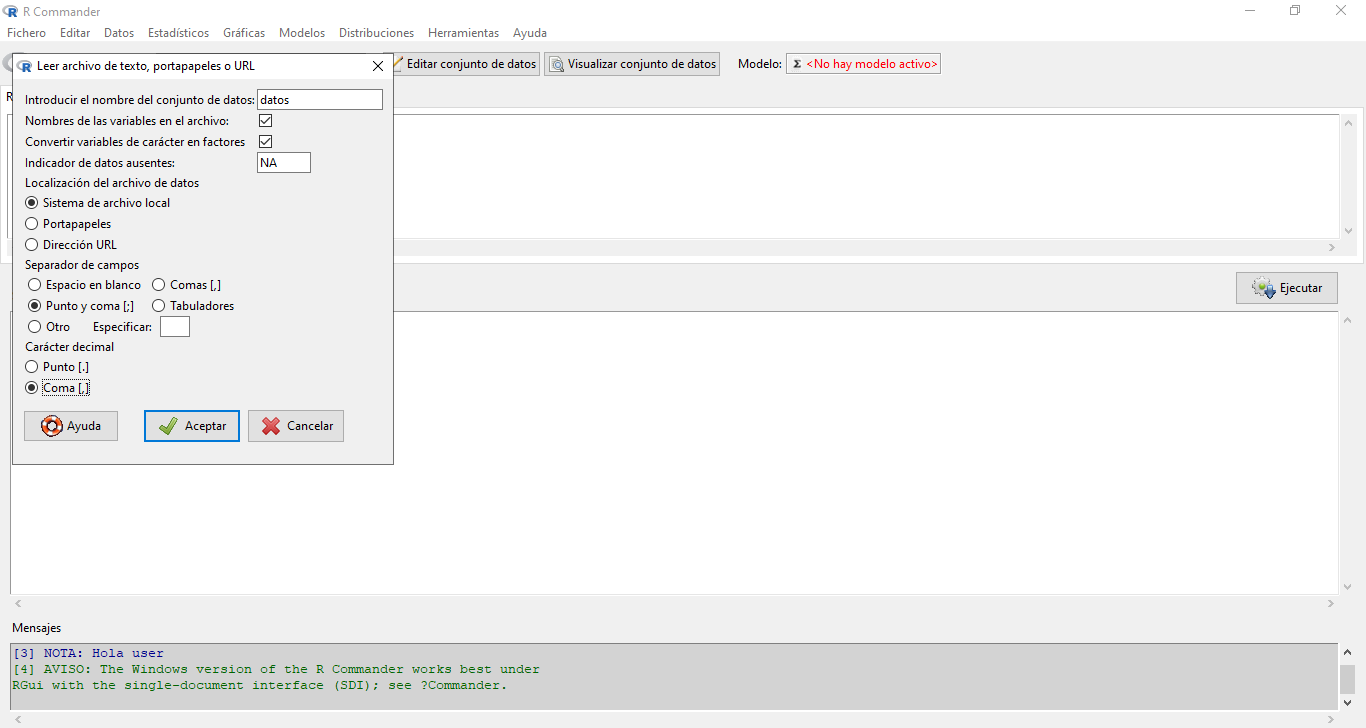
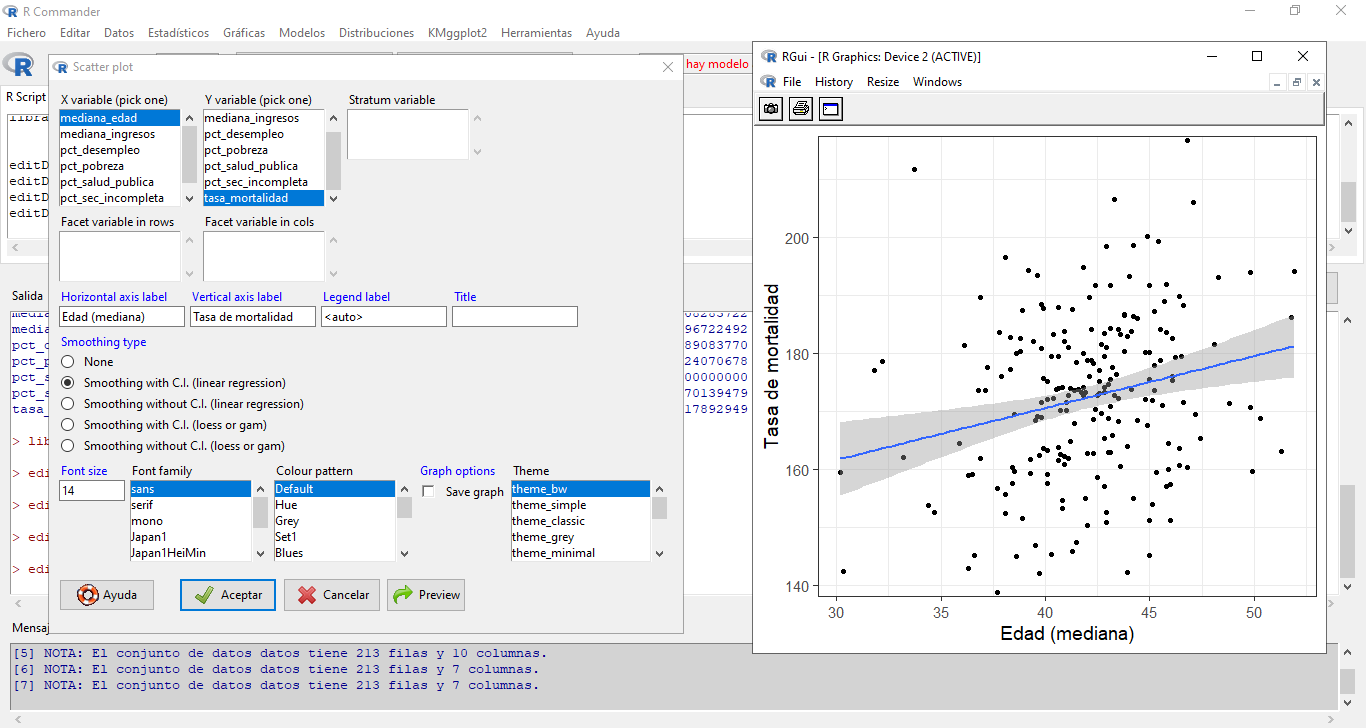
Seleccionamos el archivo “
cancer_USA.txt”, que contiene información sobre la tasa de mortalidad por cáncer para distintos condados de USA.Apretamos el botón
![]() y se abrirá una nueva ventana.
y se abrirá una nueva ventana.
 y se abrirá una nueva ventana.
y se abrirá una nueva ventana.En la nueva ventana seleccionamos las columnas de tipo caracter (
condado,estado,mediana_edad_cat) y las eliminamos.![]()
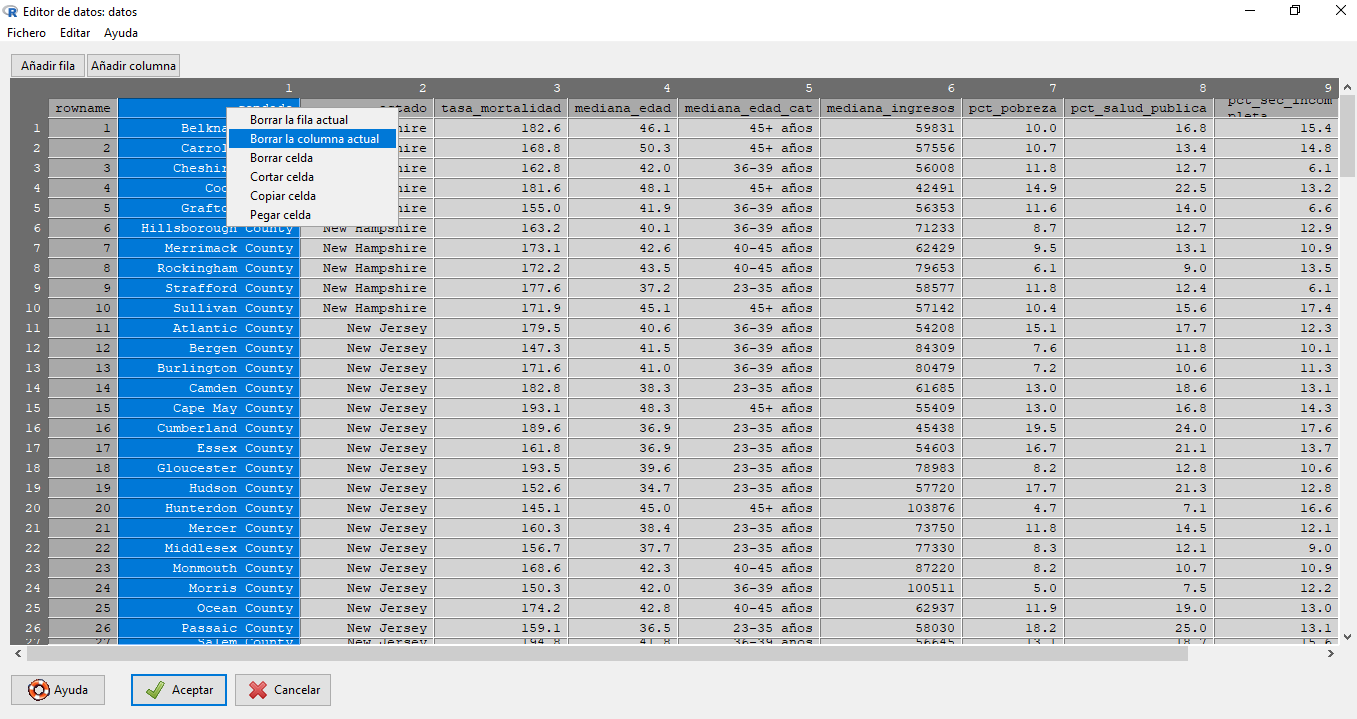
Cerramos la ventana y aceptamos los cambios.
Vamos al menú
KMggplot2 > Scatter plot:![]()
Correlación positiva entre \(X\) e \(Y\)
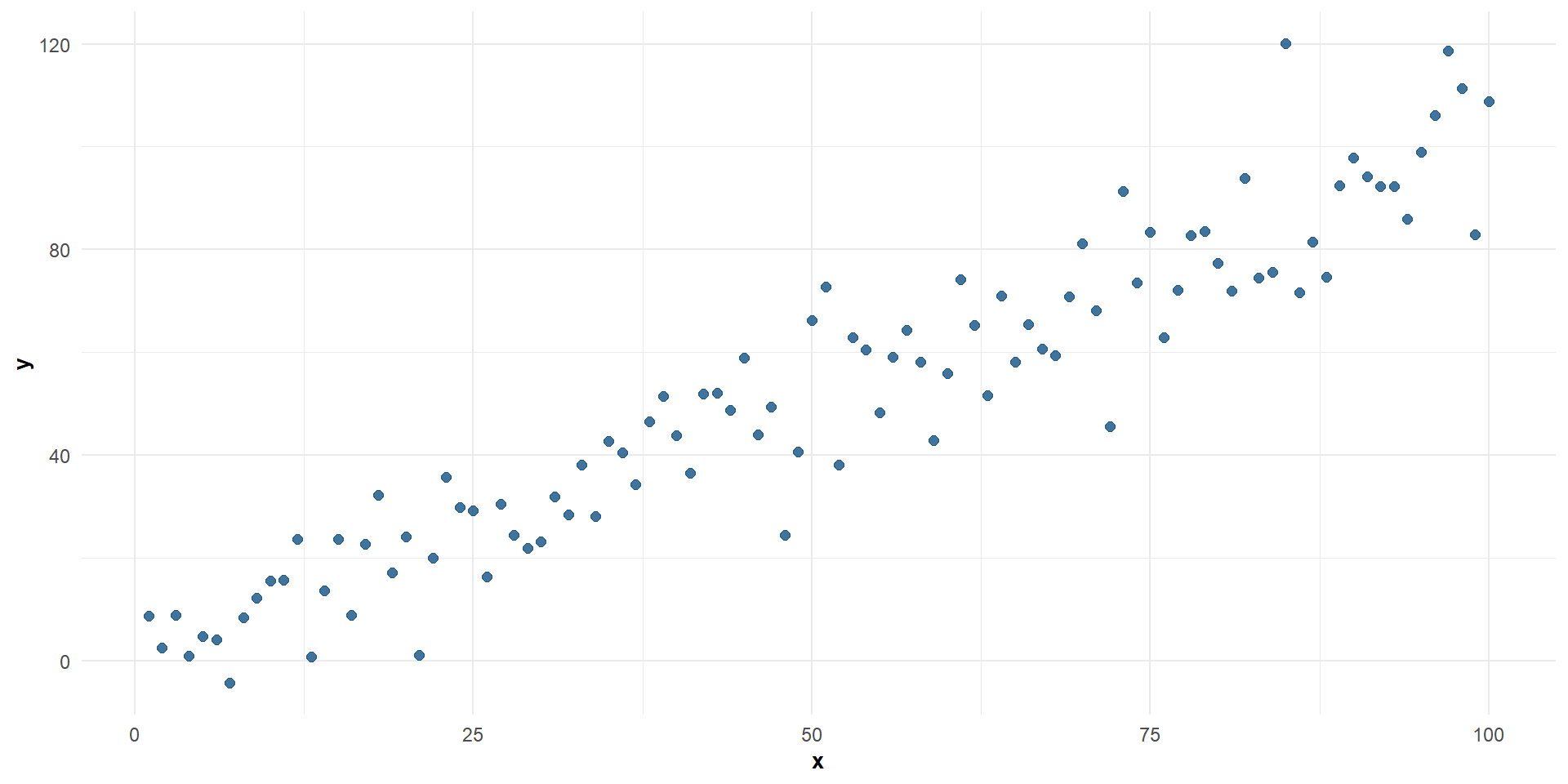
Correlación positiva fuerte entre \(X\) e \(Y\)
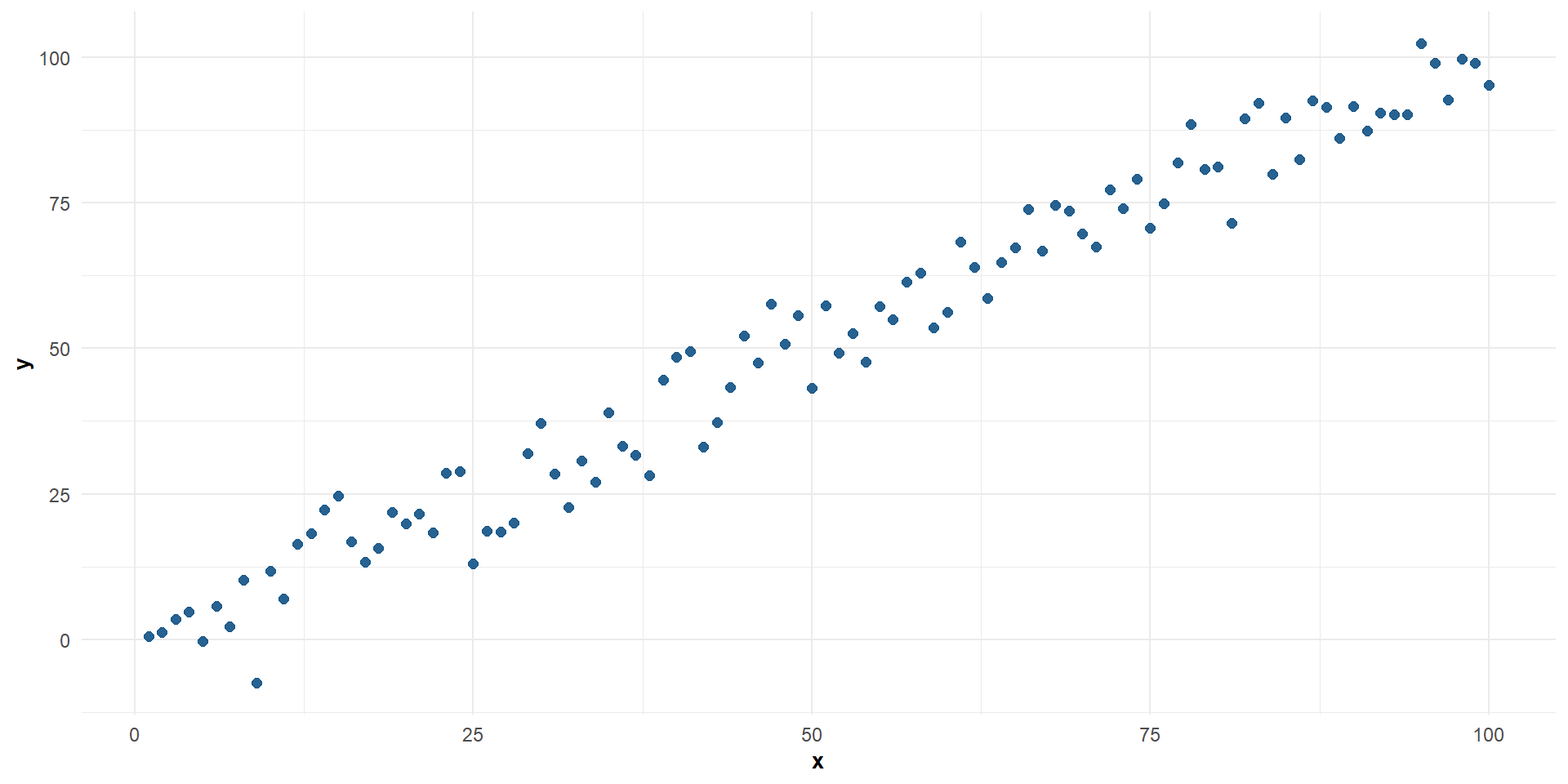
Correlación positiva perfecta entre \(X\) e \(Y\)
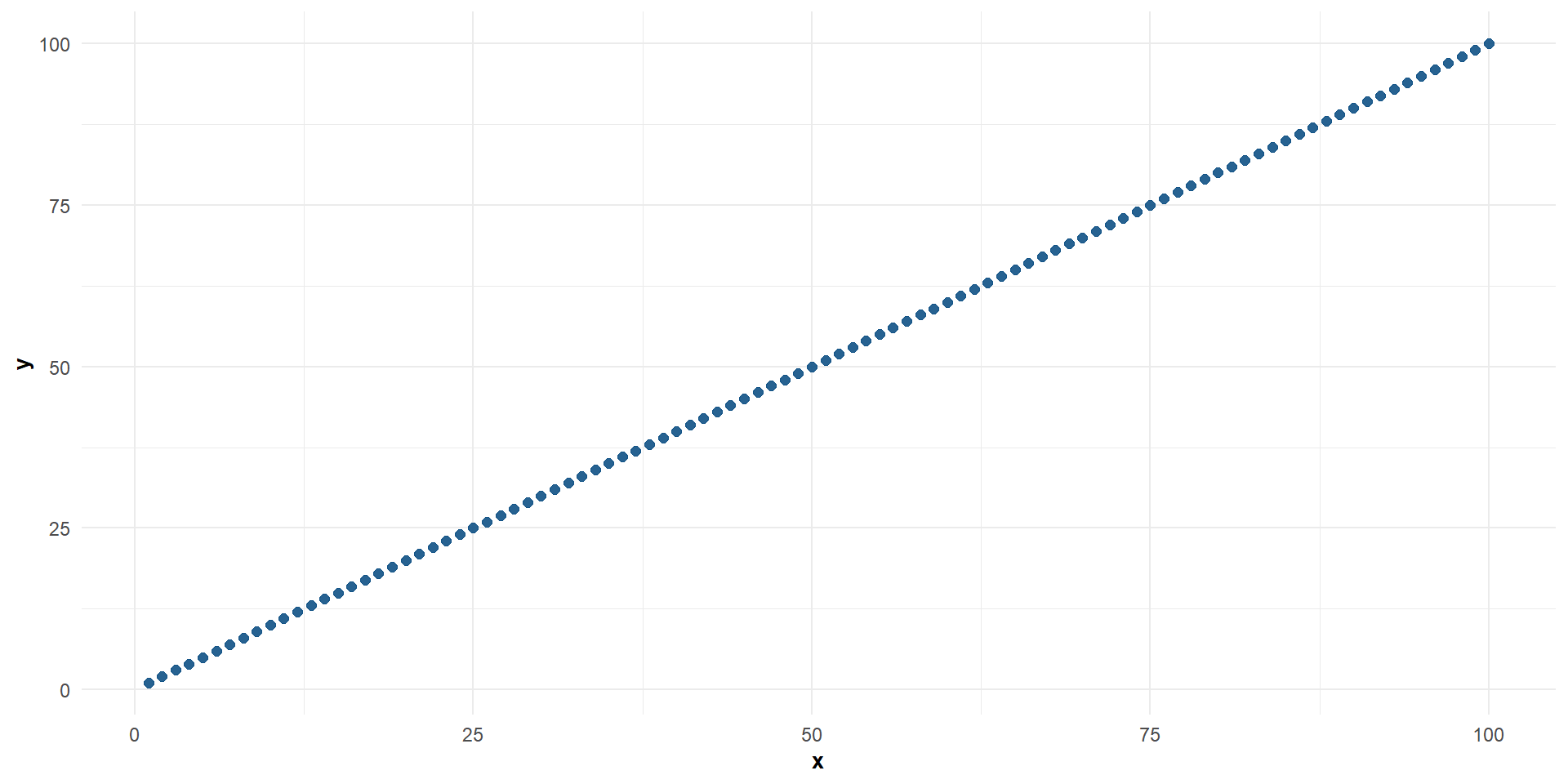
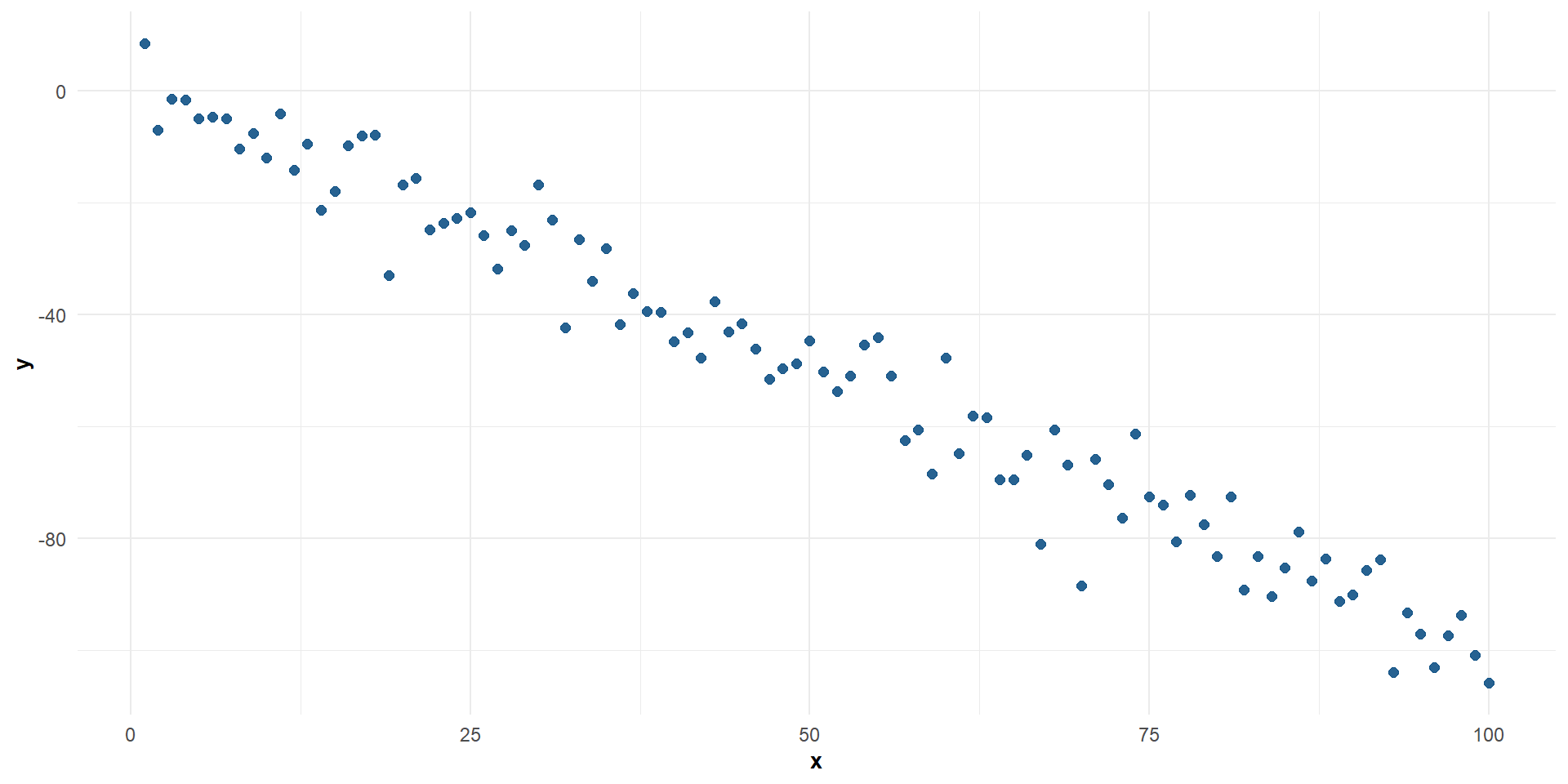
Correlación negativa entre \(X\) e \(Y\)
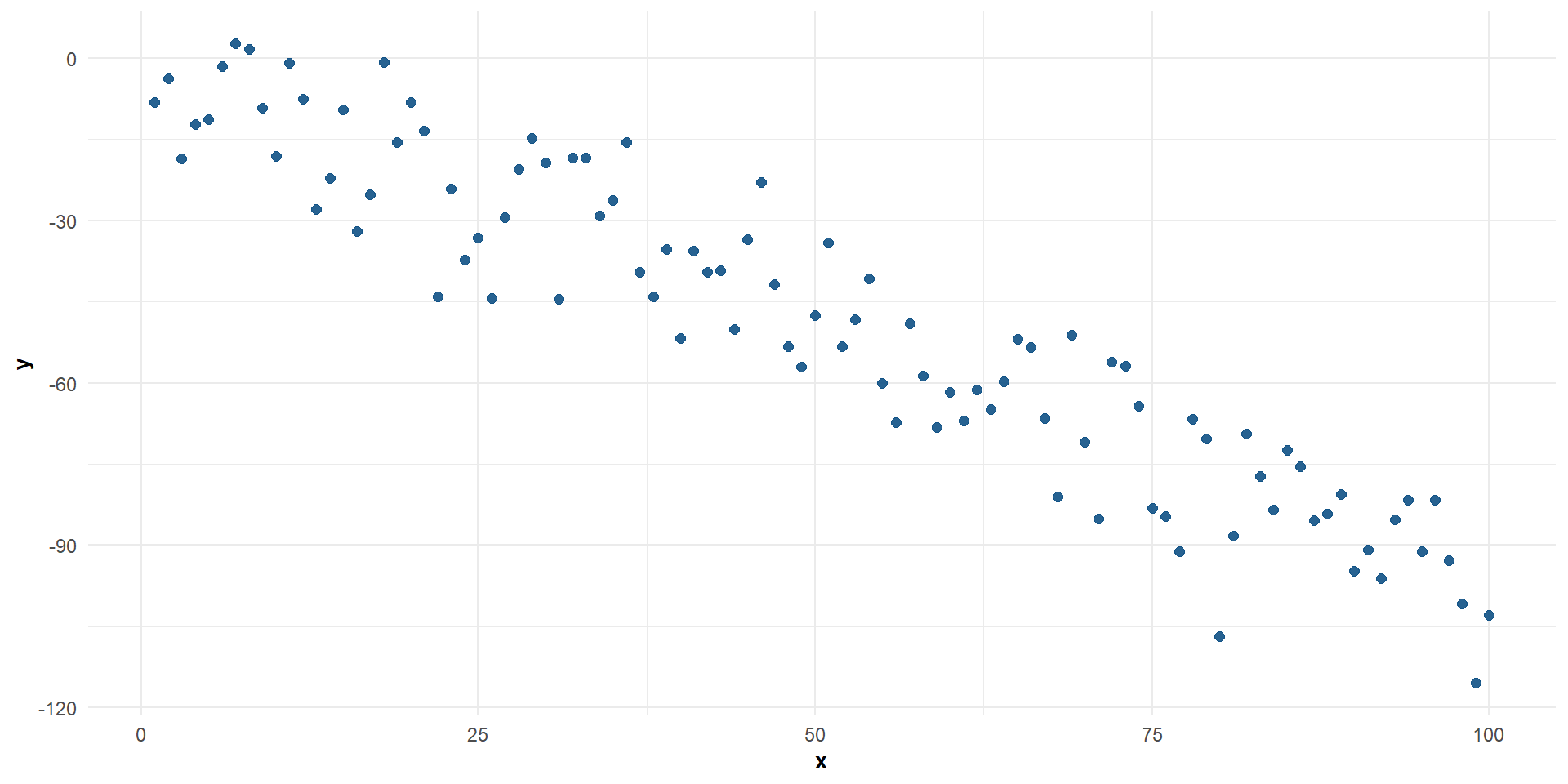
Correlación negativa fuerte entre \(X\) e \(Y\)
Correlación negativa perfecta entre \(X\) e \(Y\)
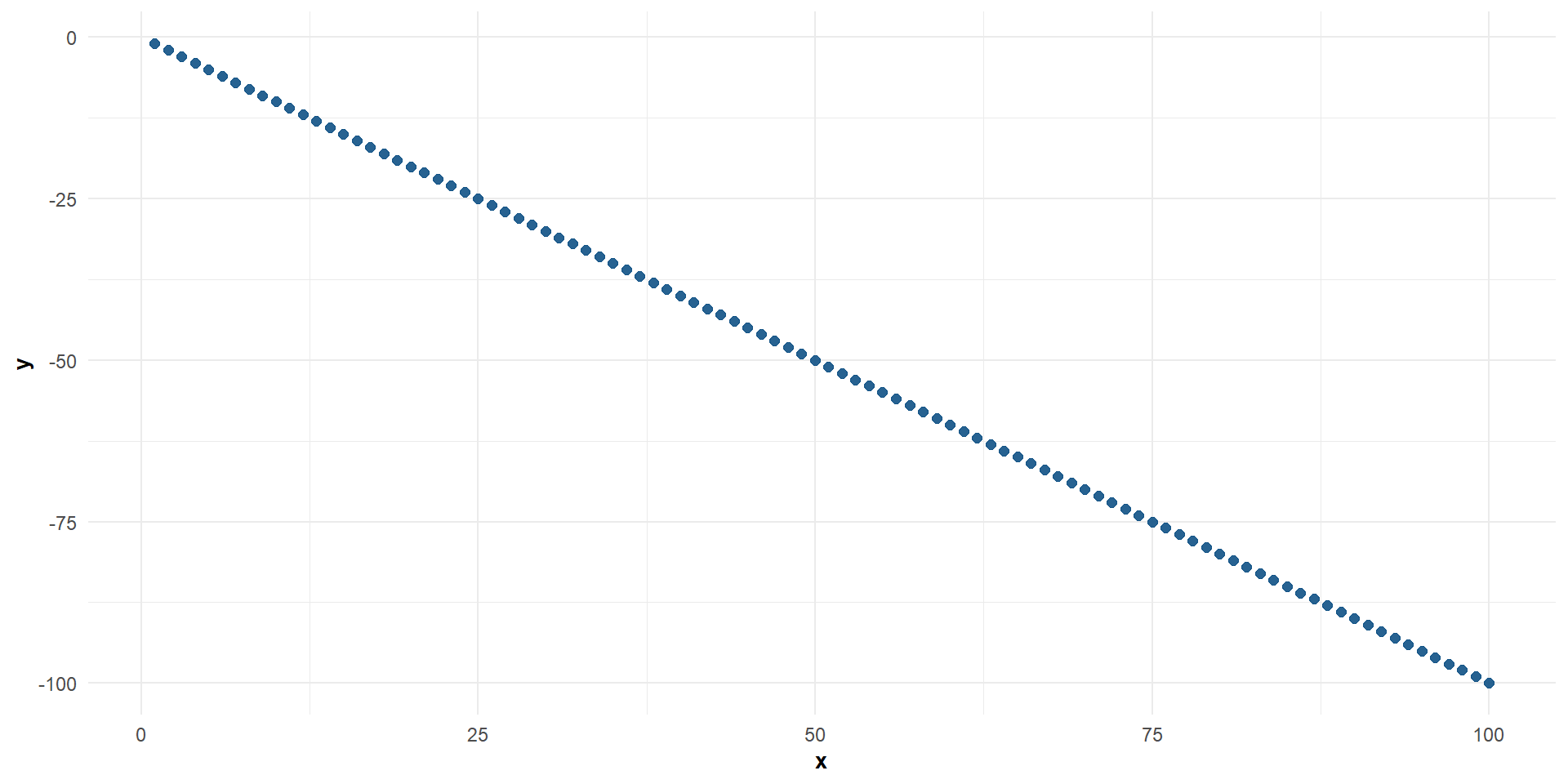
\(X\) e \(Y\) no correlacionadas
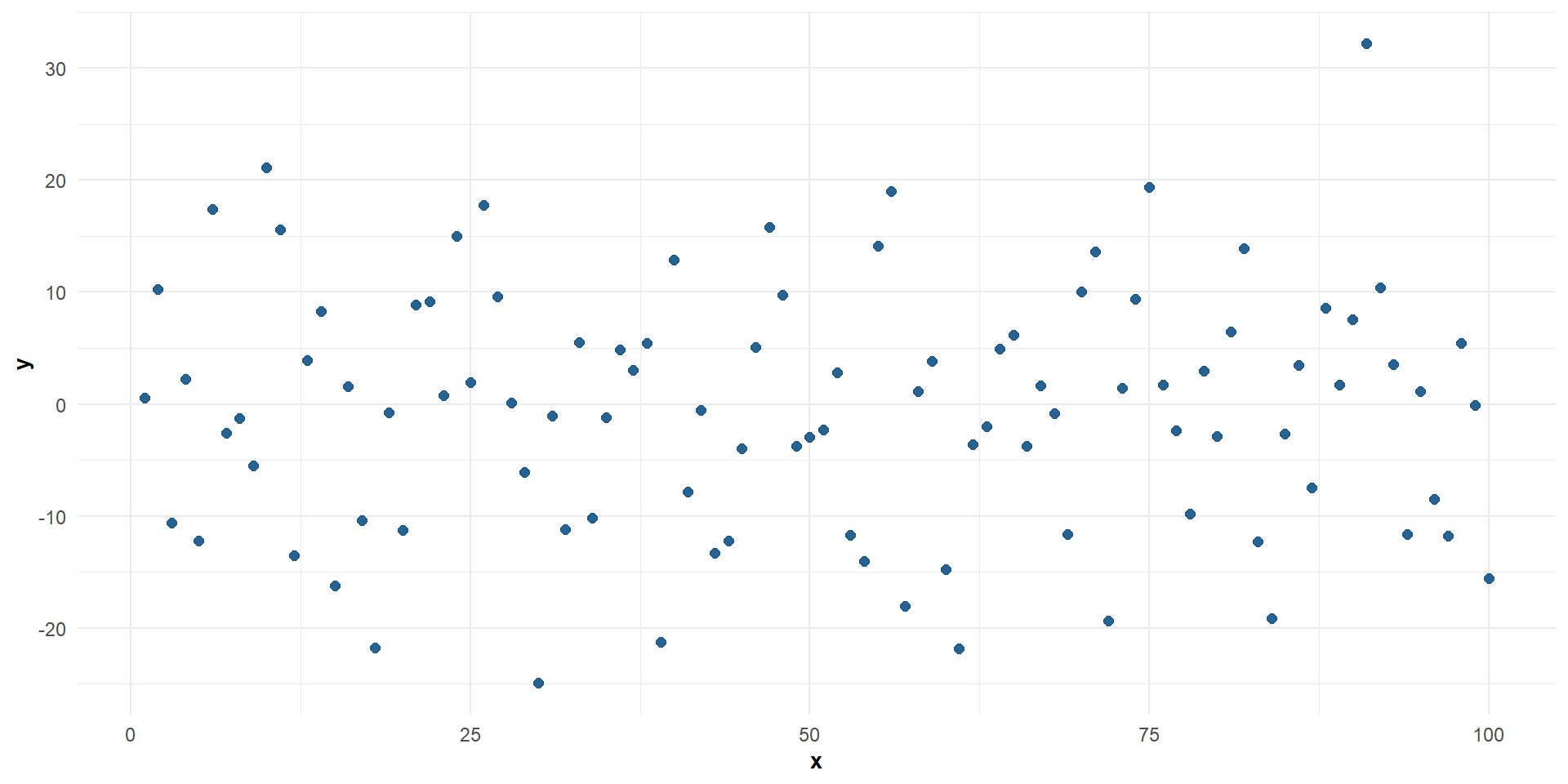
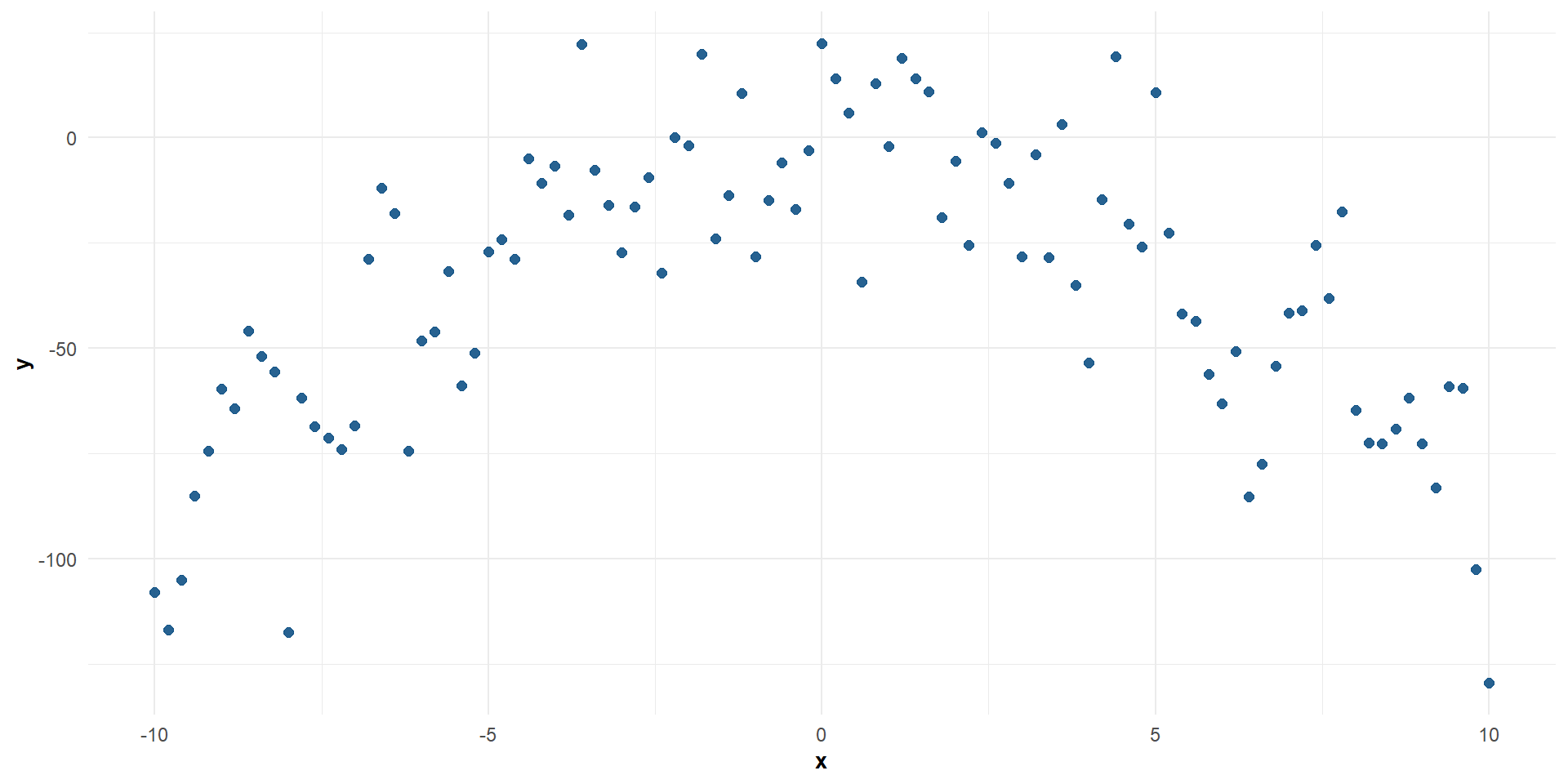
Relación no lineal entre \(X\) e \(Y\)
Ejemplo en R Commander
Ir al menú Estadísticos > Resúmenes > Test de correlación.
![]()
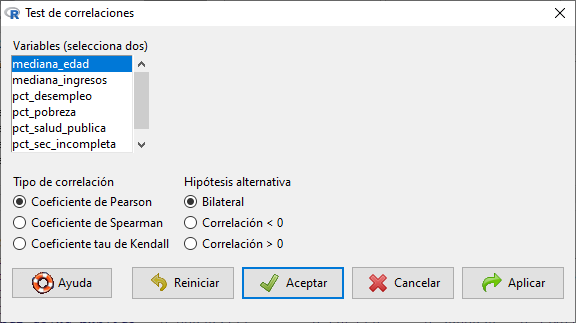
En la nueva ventana seleccionamos las variables
mediana_edadytasa_mortalidady presionamos Aceptar o Aplicar.![]()
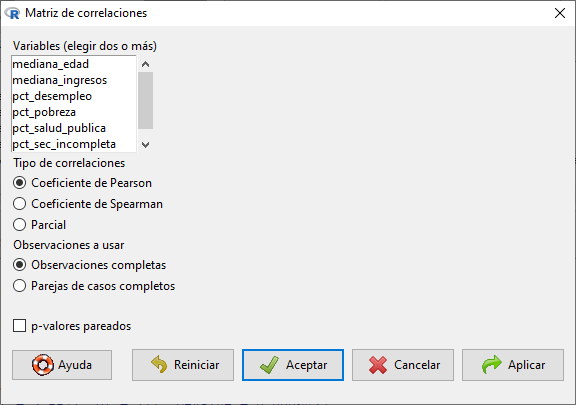
Para una matriz de correlación de todas las variables numéricas, ir al menú Estadísticos > Resúmenes > Matriz de correlaciones.
![]()
Visualización
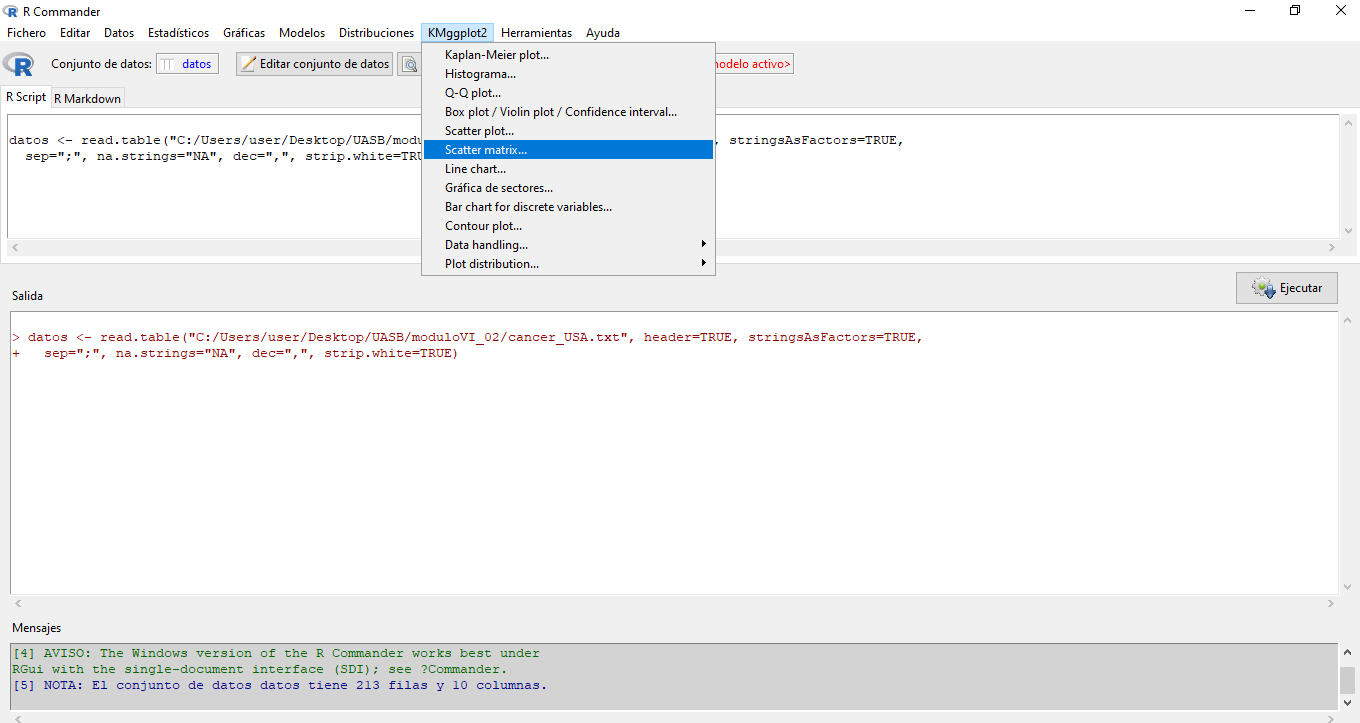
Podemos visualizar la matriz de correlación desde el menú
KMggplot2 > Scatter matrix.![]()
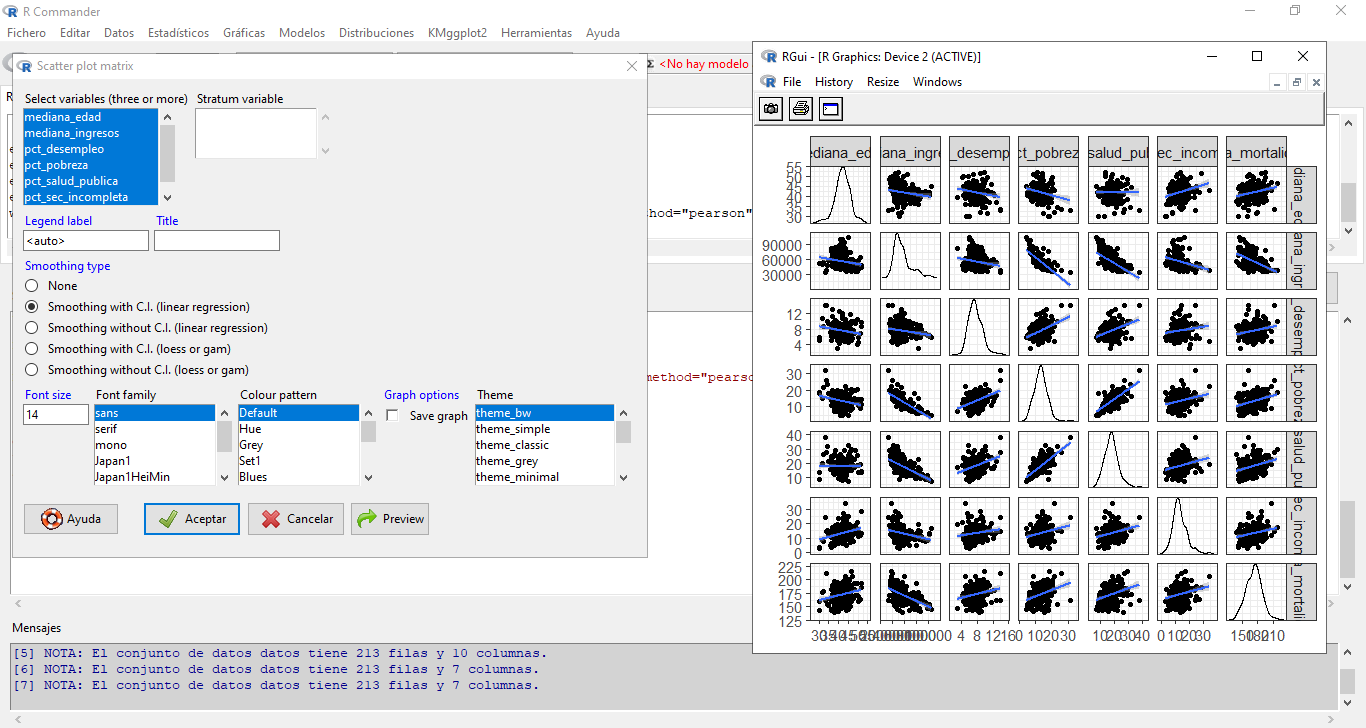
Presionamos Aceptar o Preview.
![]()
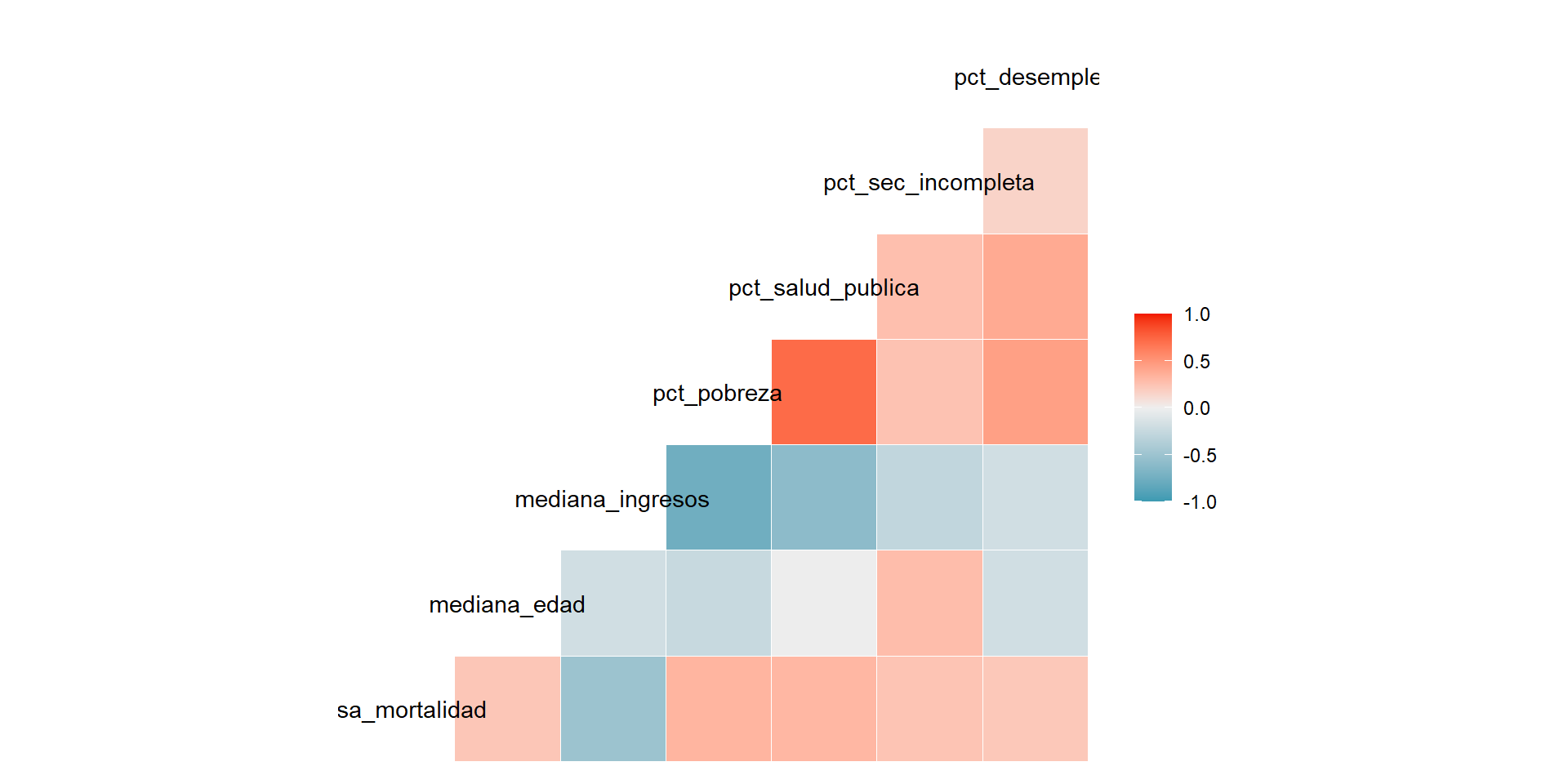
Para visualizar el correlograma escribimos
ggcorr(datos)y presionamos Ejecutar![]()
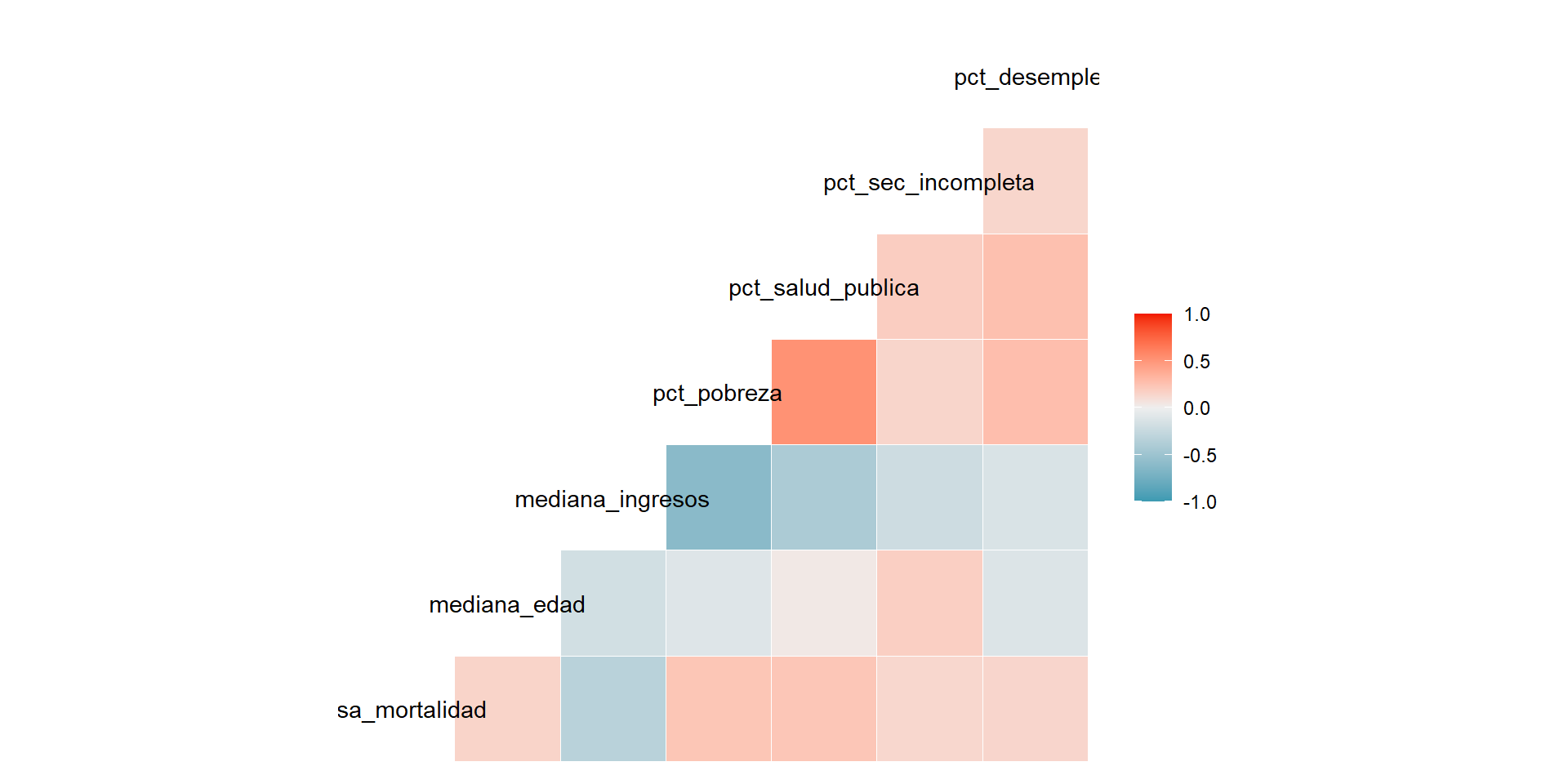
Aparecerá el siguiente gráfico:
![]()
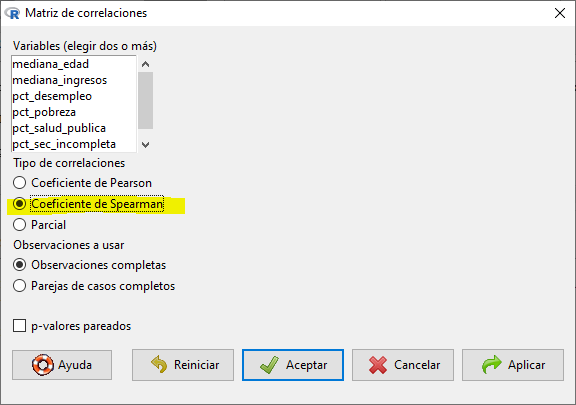
Ejemplo en R Commander
Para comparar variables numéricas mediante correlación de Spearman vamos al menú
Estadísticos > Resúmenes > Matriz de correlacionesy seleccionamos la opciónCoeficiente de Spearman.![]()
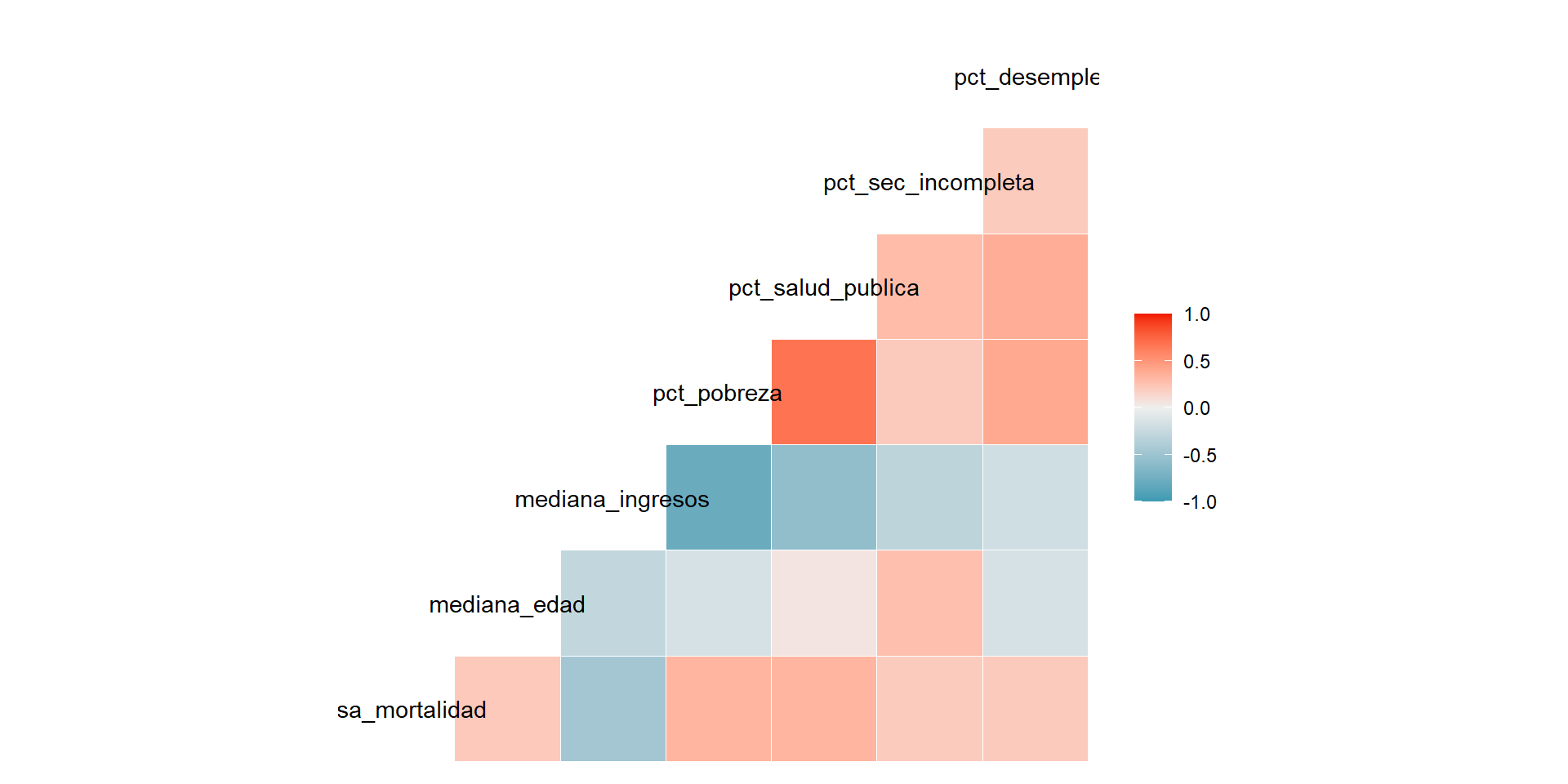
Para generar el correlograma de Spearman escribimos el siguiente código en la consola:
ggcorr(datos, method = c("pairwise", "spearman"))![]()
Para correlación de Kendall debemos ir a Estadísticos > Resúmenes > Test de correlación y seleccionar Coeficiente tau de Kendall:
![]()
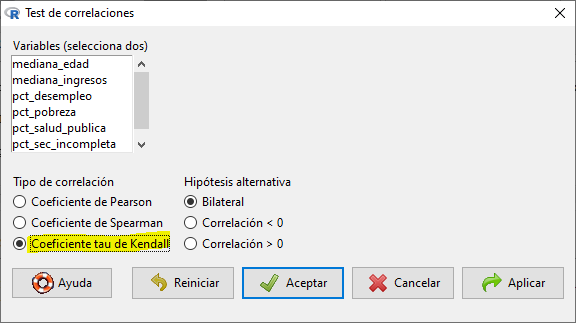
Para generar el correlograma de Kendall escribimos el siguiente código en la consola:
ggcorr(datos, method = c("pairwise", "kendall"))![]()